
こんにちは、こんぶちゃです!
私はCourseraで提供されているStanford University & DeepLearning.AIによるMachine Learning コースを受講しました。そのコースで学んだ内容を基に、ストーリー仕立てで、より楽しく、かつ理解しやすい形で機械学習の基礎を解説していきます。
- AIがどのように「考え」、動作するのかの裏側に興味がある方
- 機械学習の基本的な概念やアルゴリズムをゼロから学びたい方
- Pythonを使って、機械学習のモデルを自分で手を動かして実装してみたい方
この記事を通じて、機械学習の魅力的な世界への第一歩を踏み出しましょう。早速、始めていきましょう。
はじめに:ライナー君、正則化の世界へ
かつて数の海を渡り、線形回帰の山々を越えた我らがヒーロー、ライナー君。彼は今、新たなる挑戦に直面しています。彼のデータフィットの旅は完璧に思えたけれど、隠された罠、オーバーフィッティングが彼を待ち受けていたのです。予測の精度は高いけれど、未知のデータには脆い…。それはまるで、美味しそうに見えるが中身が空っぽのチョコレートエクレアのようなもの。
しかし、心配はいりません。ライナー君は正則化という秘密の呪文を手に入れました。この魔法は、モデルにちょうどよい複雑さを保ちつつ、過学習の魔の手からデータを守るためのもの。この新たな力を武器に、ライナー君は過学習の怪物と戦い、予測の世界にバランスをもたらそうとしています。
さあ、皆さんもこの冒険に参加しましょう。正則化の森を通って、真実のデータ分析の光を見つける旅に出発するのです。ライナー君と一緒に、オーバーフィッティングの呪いを解き、モデルの真の力を解放しましょう!
オーバーフィッティングの結び目:なぜ正則化なのか?
オーバーフィッティングは、機械学習の世界に潜む隠れた幽霊のような存在です。学習データには完璧にフィットするものの、未知のデータに対しては融通が利かなくなることを意味します。全ての問題に同じ方法を適用しようとするライナー君の姿勢と似ています。寿司を箸で食べるのは上手でも、スープを箸で飲もうとすると苦労します。
ここで重要なのが、正則化という概念です。正則化は、モデルが学習データに過剰に適合するのを防ぎ、新しいデータに対しても頑健な予測を行うための方法です。具体的には、コスト関数に正則化項を加えることで、モデルがトレーニングデータに過剰にフィットすることを避けます。
たとえば、正則化された線形回帰のコスト関数は次のように表されます:
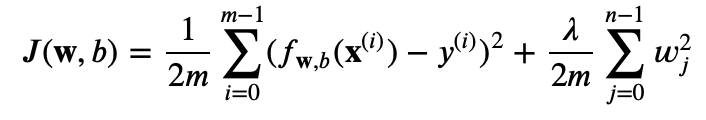
ここで、
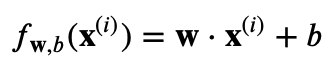
となります。この式における新しい項、
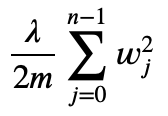
は正則化項と呼ばれ、モデルの重みが大きくなりすぎることにペナルティを与える役割を果たします。正則化パラメータ λ はこのペナルティの強さを制御します。
正則化されたロジスティック回帰においても、同様に正則化項が加えられ、コスト関数は以下のようになります:
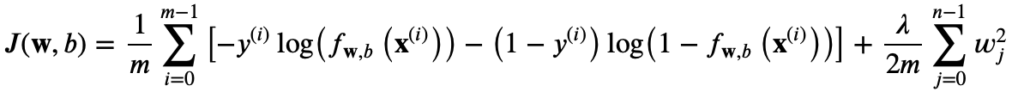
ここで
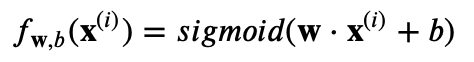
です。
これらの式における正則化項によって、ライナー君のモデルはデータに対してより一般化されたアプローチを取ることができるようになり、オーバーフィッティングの問題を避けることができます。正則化は、データの背後にある真実を見極めるための新しいコンパスとなり、微妙なバランスを取りながら、信頼できる予測へと導く小さな「ひねり」が大きな違いを生み出します。
Pythonでライナー君のクエストを支援
ライナー君が正則化の技術を磨くためには、理論だけでなく実際のコードでその力を試す必要があります。ここではPythonを用いて、正則化回帰モデルを実装する二つの方法を紹介します。
まず、今回比較検証を行うためのデータの準備をします。sklearnのライブラリー内の乳がんのデータセットを読み込み、トレーニングセットとテストセットに分割し、スケーリング(標準化)を行います
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_breast_cancer
# 乳がんデータセットを読み込み
data = load_breast_cancer()
X = data.data
y = data.target
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# データのスケーリング
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)手動での実装
手動でロジスティック回帰モデルに正則化を適用する方法です。
def compute_gradient_logistic_reg(X, y, w, b, lambda_):
m, n = X.shape
dj_dw = np.zeros(n)
dj_db = 0.0
for i in range(m):
f_wb_i = 1 / (1 + np.exp(-(np.dot(X[i], w) + b)))
err_i = f_wb_i - y[i]
dj_dw += err_i * X[i]
dj_db += err_i
dj_dw = dj_dw / m + (lambda_ / m) * w
dj_db = dj_db / m
return dj_db, dj_dw
num_iter = 1000 # 繰り返し回数
alpha = 0.01 # 学習率
lambda_ = 1.0 # 正則化パラメータ
# パラメータを初期化
w = np.random.rand(X_train_scaled.shape[1]) # w のサイズを特徴量の数に合わせる
b = 0.0 # b の初期値
for i in range(num_iter):
# 勾配を計算
dj_db, dj_dw = compute_gradient_logistic_reg(X_train_scaled, y_train, w, b, lambda_)
# パラメータを更新
w = w - alpha * dj_dw
b = b - alpha * dj_db
# モデルのスコアを計算する関数
def compute_score(X, y, w, b):
predictions = 1 / (1 + np.exp(-(np.dot(X, w) + b)))
predictions = predictions >= 0.5 # 0.5以上をクラス1と予測
accuracy = np.mean(predictions == y) # 正解率を計算
return accuracy
# トレーニングセットとテストセットでスコアを計算
train_score = compute_score(X_train_scaled, y_train, w, b)
test_score = compute_score(X_test_scaled, y_test, w, b)
print('トレーニングセットのスコア:', train_score)
print('テストセットのスコア:', test_score)出力結果:
トレーニングセットのスコア: 0.969
テストセットのスコア: 0.974
scikit-learnを用いた実装
次に、scikit-learnライブラリを使ってモデルを簡単にトレーニングする方法を見てみましょう。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
# 仮のデータセットを生成
np.random.seed(0)
X = np.random.rand(100, 3)
y = X @ np.array([1.5, -2.0, 1.0]) + 0.5 * np.random.randn(100)
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 正則化パラメータを設定
alpha = 1.0
# リッジ回帰モデルをトレーニング
ridge_model = Ridge(alpha=alpha)
ridge_model.fit(X_train, y_train)
# スコアを表示
print('sklearnのRidgeモデルのスコア')
print('Training set score:', ridge_model.score(X_train, y_train))
print('Test set score:', ridge_model.score(X_test, y_test))出力結果:
トレーニングセットのスコア: 0.987
テストセットのスコア: 0.974
手動での実装とscikit-learnでの正則化(Ridge)において、同等の正解率になることが確認できます。
綱渡り:正則化モデルの評価
正則化モデルがどれほど優れているかを判断するには、綱渡りのような評価が必要です。ライナー君が綱の上を安全に渡るためには、バランスを取る術を知る必要があります。同じように、私たちも混同行列やROC曲線というツールを使って、モデルのバランスを正確に測定します。
混同行列は、モデルが予測をどの程度正確に行ったかを見るためのマトリックスです。ROC曲線は、モデルがさまざまなしきい値でどのようにパフォーマンスするかを示します。これらのツールは、モデルの真の能力を理解するために不可欠です。
以下のサンプルコードは、ライナー君が正則化モデルのパフォーマンスを評価するために使うことができます。
# 上記のscikit-learnの検証データを用いています。上記を実行後をベースにしています
# テストデータの予測
predictions_sklearn = model.predict(X_test_scaled)
# 混同行列の作成
conf_matrix_sklearn = confusion_matrix(y_test, predictions_sklearn)
# 混同行列をheatmapで表示
plt.figure(figsize=(10, 7)) # グラフのサイズを設定
sns.heatmap(conf_matrix_sklearn, annot=True, fmt="d", cmap="Blues",
xticklabels=data.target_names, yticklabels=data.target_names)
plt.title('Confusion Matrix')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()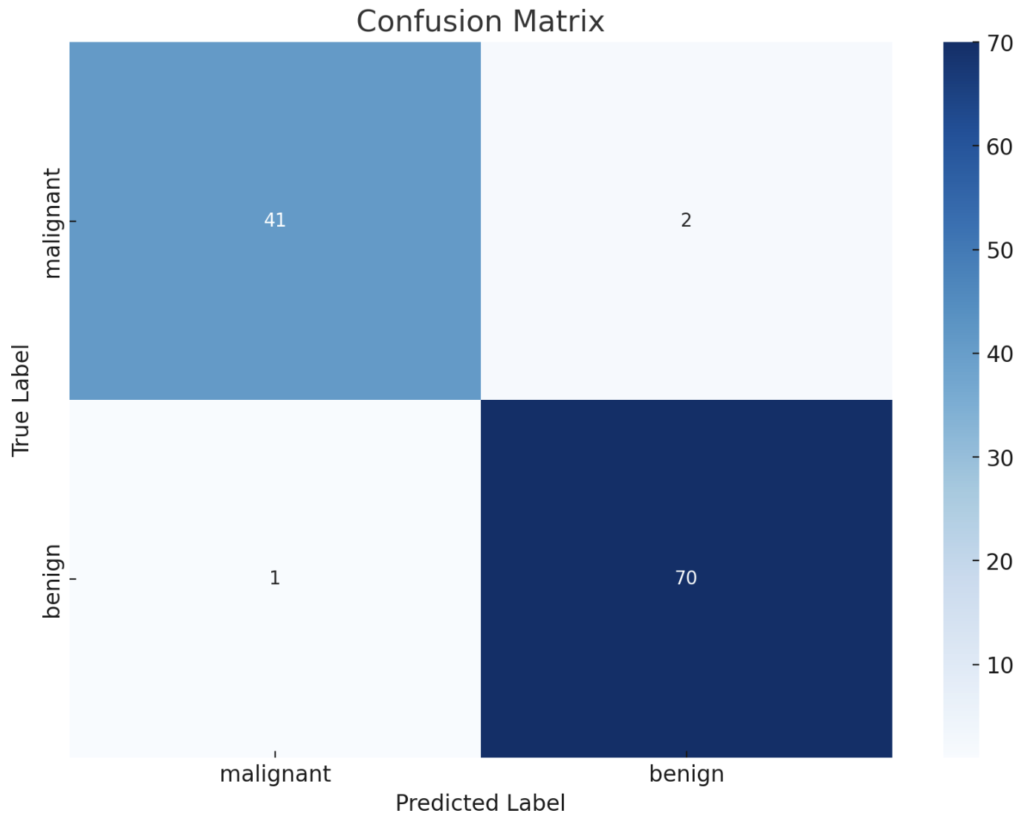
from sklearn.metrics import roc_curve, roc_auc_score
# ROC曲線のデータを計算
fpr, tpr, thresholds = roc_curve(y_test, model.predict_proba(X_test_scaled)[:, 1])
# ROC曲線のスコアを計算
roc_auc = roc_auc_score(y_test, model.predict_proba(X_test_scaled)[:, 1])
# ROC曲線をプロット
plt.figure(figsize=(6, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()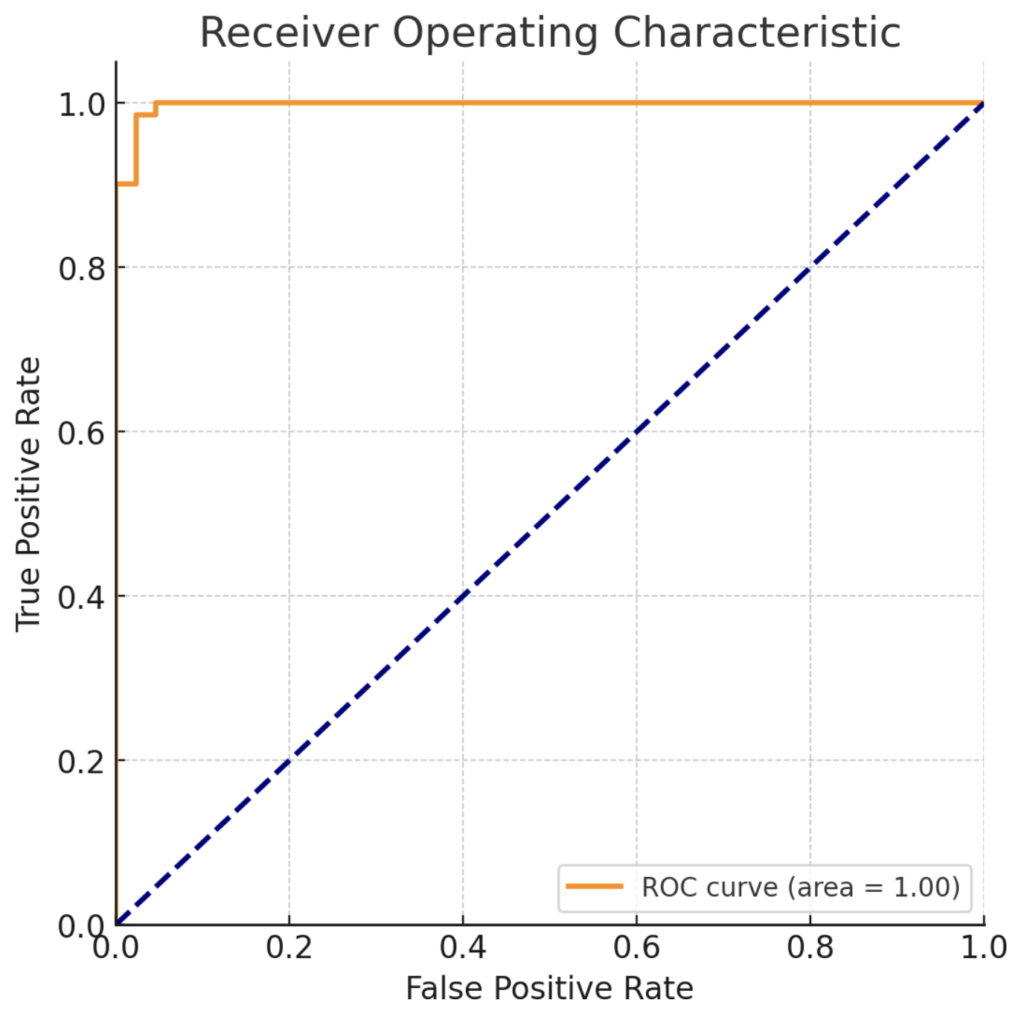
これらのコードを通じて、ライナー君はモデルがどの程度分類問題において適切な予測を行っているかを視覚的に把握することができます。ROC曲線の下の面積(AUC)が大きいほど、モデルのパフォーマンスは良いと評価されます。
実践:正則化の魔法を体験する
いよいよ、あなた自身の手で正則化の魔法を振るときが来ました。このセクションでは、実際のデータセットを使って自分だけの正則化回帰モデルを構築し、それを用いて分類問題を解決するチャレンジを行います。
データサイエンティストのライナー君として、以下のステップで冒険を進めましょう:
- データセットの選定: KaggleやUCI Machine Learning Repositoryから、あなたにとって興味深いデータセットを選びます。
- データの前処理: データを掃除し、必要な変換を行い、トレーニングセットとテストセットに分割します。
- モデルの構築: 正則化パラメータを選んでリッジ回帰またはラッソ回帰モデルを構築します。
- パフォーマンスの評価: トレーニングセットでモデルを訓練し、テストセットでモデルのパフォーマンスを評価します。
- 結果の分析: 混同行列やROC曲線を使って、モデルの性能を分析します。
この冒険を成功させるためには、以下の点に注意してください:
- 正則化パラメータの選択は、モデルの複雑さと一般化能力のバランスをとる鍵です。
- トレーニングデータに対して非常にうまくフィットするモデルも、テストデータでうまく機能しないことがあります。
- 評価指標はモデルの性能を正確に把握するために重要です。AUCが高ければ高いほど、モデルは一般に良い性能を示しています。
ライナー君と同じように、あなたもデータサイエンティストとしての旅を楽しんでください。この実践を通じて、正則化の力を体験し、より堅牢なモデルを作る魔法を身につけましょう。そして、あなたの成果を共有して、コミュニティの他のメンバーと知識を共有してください。成功への道は共有することから始まります。
まとめと次なる探求への一歩
今回の冒険で、ライナー君は正則化の魔法を使いこなし、モデルの性能を見極める術を身につけました。彼はデータの背後にある真実を探り、オーバーフィッティングという罠から逃れるために、数学の力を利用しました。
しかし、データサイエンスの旅はここで終わりではありません。ライナー君はこれからさらに大きな挑戦に向かいます。「特徴スケーリングと多項式回帰」です。これらのテクニックは、モデルがデータをどのように理解し、解釈するかに大きな影響を与えるため、とても重要です。
特徴スケーリングによって、ライナー君は異なるスケールの特徴を調和させ、多項式回帰を用いて複雑なデータ関係を捉えることができます。これらの技法によって、彼の予測はさらに洗練され、精度が増すでしょう。
ライナー君と一緒に、次回は特徴スケーリングの秘密と多項式回帰の力を探求しましょう。新しいデータの形状を整え、予測の精度を向上させる方法を学び、あなたのデータサイエンスの武器庫に加えてください。探求の旅は続きます。次回の更新で、ライナー君と共にさらなる知識の地平線へと進んでいきましょう!


コメント