
こんにちは、こんぶちゃです!
私はCourseraで提供されているStanford University & DeepLearning.AIによるMachine Learning コースを受講しました。そのコースで学んだ内容を基に、ストーリー仕立てで、より楽しく、かつ理解しやすい形で機械学習の基礎を解説していきます。
- AIがどのように「考え」、動作するのかの裏側に興味がある方
- 機械学習の基本的な概念やアルゴリズムをゼロから学びたい方
- Pythonを使って、機械学習のモデルを自分で手を動かして実装してみたい方
この記事を通じて、機械学習の魅力的な世界への第一歩を踏み出しましょう。早速、始めていきましょう。
はじめに:ライナー君、新たなる謎に挑む
前回までの冒険で、ライナー君は線形回帰とその進化形である重回帰分析の山々を軽やかに越えてきました。しかし、知識の海は広大で、まだまだ未知の領域が広がっています。今回、ライナー君は新たな挑戦に目を輝かせています。その名も「分類問題」。数値を予測する旅から、今度は「はい」か「いいえ」、つまりカテゴリを分類する謎解きに挑みます。
「でも、ライナー君、分類問題って一体どうやって解くの?」と思うかもしれませんね。ここで登場するのが、ロジスティック回帰です。この魔法のような手法は、データが属するカテゴリーを予測するのにピッタリ。数値予測の線形回帰とは異なり、ロジスティック回帰ははっきりとした「分類」のための呪文を唱えるのです。
「分類の魔法使いになれるなんて、わくわくする!」ライナー君は意気揚々としていますが、この旅が平坦な道のりだけではないことを、彼も我々も知っています。複雑なデータの森をナビゲートし、正しいカテゴリにデータを導くためには、ロジスティック回帰の秘密を解き明かし、その力を自分のものにしなければなりません。
では、ライナー君と一緒に、この新しい冒険に出発しましょう。分類問題の謎を解き、ロジスティック回帰の魅力を全て探り尽くす旅が、今、始まります。
ロジスティック回帰の謎:分類の冒険
ライナー君の新たな冒険は、分類問題の神秘的な世界へと足を踏み入れることから始まります。では、分類問題とは何でしょうか?簡単に言えば、メールがスパムかそうでないか、写真に猫が写っているかどうかといった、事物をカテゴリーに分ける問題のことです。この種の問題は、日常生活で実に頻繁に遭遇しますが、ロジスティック回帰はこれらの謎を解く鍵を握っているのです。
シグモイド関数:ロジスティック回帰の鍵
シグモイド関数は、ロジスティック回帰の核心をなす魔法の一種で、その美しいS字型のカーブは数学者とデータサイエンティストの間で広く認識されています。関数の数学的な形は
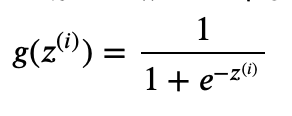
と表され、ここで e は自然対数の底、z は線形回帰の出力(下記)です。
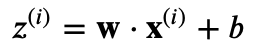
この魔法の式が何をするかというと、大きな正の数を1に近づけ、大きな負の数を0に近づけ、そしてその間の数値を滑らかな曲線に沿って0から1の間にマッピングします。これにより、ロジスティック回帰モデルは任意の実数値を取る入力を、0と1の間の確率値に変換することができます。結果として、出力を2つのカテゴリーに分類する際の「確率」として解釈することが可能になるのです。
グラフにすると、シグモイド関数は中央で急激に変化し、z=0 の時にちょうど0.5になります。これは、モデルがそのサンプルが片方のカテゴリに属する確率が50%と予測していることを意味します。z の値が大きくなるほど、関数の値は1に近づき、z の値が小さくなるほど0に近づきます。したがって、シグモイド関数は分類問題に適しており、特に2つのクラスにデータを分類する場合に有用です。
シグモイド関数のグラフを見ると、どのようにして入力値が確率に変換されるかが視覚的にも明確になります。関数のこの滑らかなS字型の性質は、微分可能であるため、勾配降下法などの最適化アルゴリズムで効率的に使用することができます。
グラフを描いて、シグモイド関数の美しい曲線を直接見てみましょう。
import numpy as np
import matplotlib.pyplot as plt
# シグモイド関数を定義する
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# プロットするために-10から10までの値の範囲を生成する
z = np.linspace(-10, 10, 100)
# これらの値のシグモイドを計算する
g_z = sigmoid(z)
# プロットを作成する
plt.figure(figsize=(10,6))
plt.plot(z, g_z, label="Sigmoid Function")
plt.title('Sigmoid Function')
plt.xlabel('z')
plt.ylabel('g(z)')
plt.grid(True)
plt.legend()
plt.show()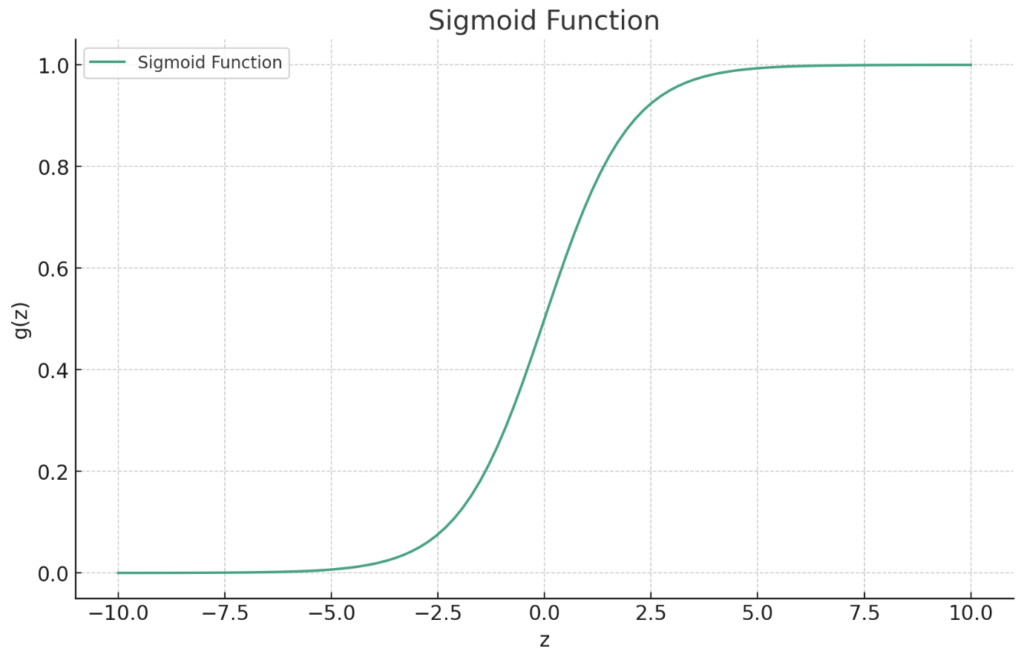
ロジスティック回帰での魔法のコスト計算
ライナー君が今回直面しているのは、ロジスティック回帰のコスト関数という、まるで古代の呪文のような数式です。この呪文は、モデルがどれだけデータをうまく学習しているかを測るバロメーターの役割を果たします。呪文の全文は
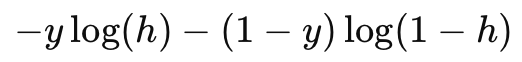
(コードで記載)-y * np.log(h) - (1 - y) * np.log(1 - h)
というものですが、これをライナー君流に解釈してみましょう。
まず、h はモデルが予測した確率で、つまりライナー君が宝探しで目指す宝の地図上の位置です。y は実際の答え、つまり宝が実際にあるかどうかを示します(1なら宝があり、0なら宝はなし)。ライナー君の目標は、予測したhが実際のyにできるだけ近づくことです。
ここで、コスト関数の第一部分 -y * np.log(h) は、ライナー君が「宝あり!」と予測した時の正確さを測ります。予測が正しければ(hが1に近い時)、この部分のコストは小さくなります。しかし、予測が外れていれば(hが0に近い時)、コストは無限大に向かいます。これは、宝があると言い張るのに、全く根拠がない場合には大きなペナルティを受けるということです。
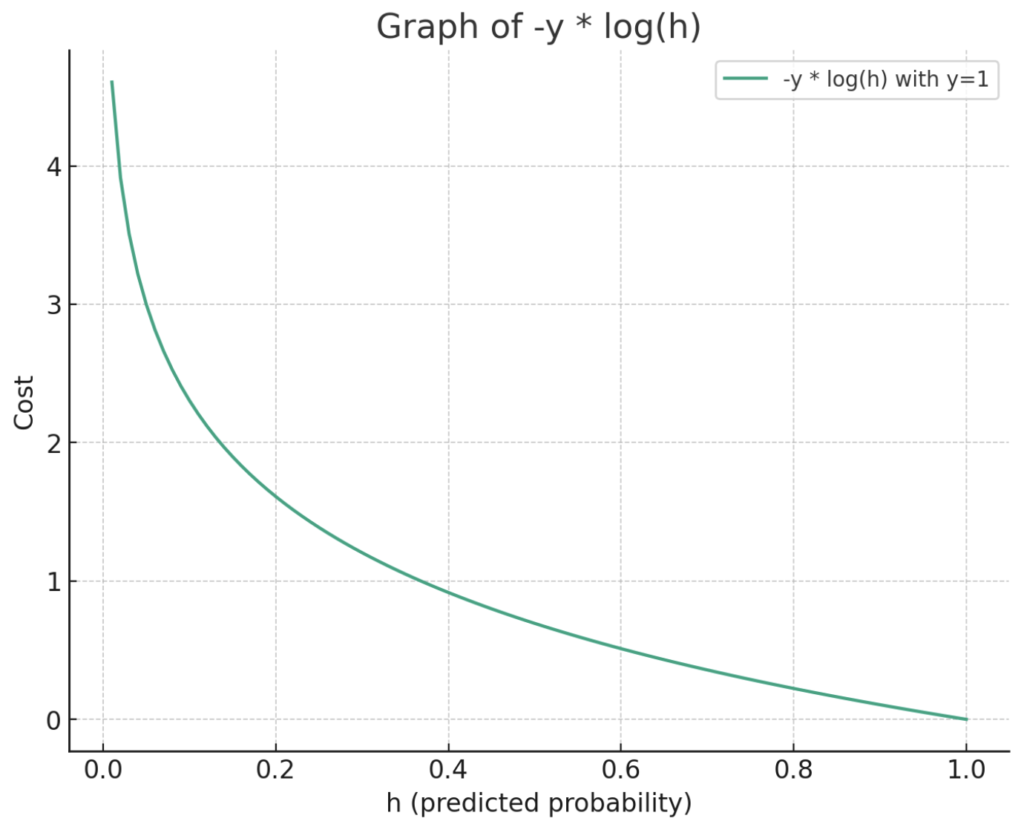
次に、コスト関数の第二部分 - (1 - y) * np.log(1 - h) は、ライナー君が「宝なし!」と予測した時の正確さを測ります。この場合も同様に、予測が正しければコストは小さく、予測が外れていればコストは大きくなります。
この呪文を合唱することで、ライナー君は予測をどんどんと実際の値に近づけていくことができるのです。コストが小さいほど、宝の正確な位置を示す地図が正確であるということ。ライナー君の目標は、このコストをできるだけ小さくすることで、最も信頼できる宝の地図を手に入れることです。
コスト関数J:
mはサンプル数。[ ]部の平均と同じことになります
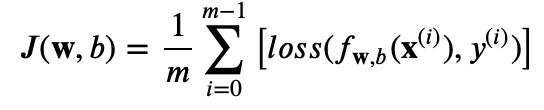
lossの部分(上記の呪文部分):
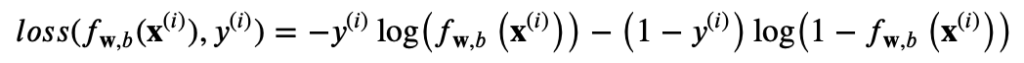
fw,b(x(i))とhは同じ、モデルによって予測された確率。
勾配降下法:謎解きの道標
ライナー君の冒険は、地図の予測地点hと、実際に宝が隠された位置yとの間の違いを探ることから始まります。この差異は、彼が宝探しの道中で正しい方向に向かっているのか、それとも迷い込んでしまっているのかを示す重要な手がかりとなります。勾配降下法という名の頼もしい道標は、この手がかりを使って、ライナー君が地図を正確なものへと少しずつ修正していく手助けをします。
gradient_descent関数、すなわち地図を緻密にするための魔法の言葉は、ライナー君がこれまでの探検で蓄積した経験(データX)と、予測された宝の場所と実際の場所との間の差(h - y)を活用します。この魔法は、彼の地図上のどの地点を、どのように修正すればよいかを計算します。具体的には、経験データXの転置(X.T)と予測と実際の差の積を取ることで、各特徴量が最終的な予測にどう影響するかを探ります。これは、彼の地図上で特定の箇所を修正するための具体的な指示となります。
そして、この計算で得られる値をデータ点の総数(y.shape[0])で割ることにより、地図の修正すべき量を全データ点にわたる平均値として算出します。これにより、ライナー君は全ての経験を等しく反映させながら、地図を正しい方向へと修正することができます。この精緻化されたプロセスは、ライナー君の地図が実際の宝の位置にどれだけ近づいているかを示すコストを最小限に抑えることを目指します。
gradient_descent関数: np.dot(X.T, (h - y)) / y.shape[0]
数学的な表現:
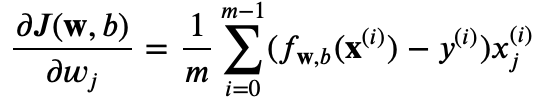
この魔法の言葉np.dot(X.T, (h - y)) / y.shape[0]を駆使することで、ライナー君は最終的に最も信頼できる宝の地図を作成し、宝探しの冒険における成功への道を確かなものとします。この旅は単なる地図の修正作業ではなく、未知の地を探検し、宝を見つけ出す知恵と勇気の証となるのです。
この精緻化された探求の次の段階では、ライナー君は実際に地図の修正作業を行います。具体的には、彼は計算された勾配を使って、地図上の重み(宝を示すX印の精度)とバイアス(宝への近さの見積もり)を更新します。更新の呪文は、簡単だが強力で、重み w とバイアス b には次のように囁かれます:
重み w の更新式:
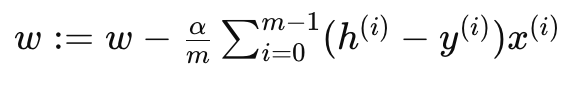
バイアス b の更新式:
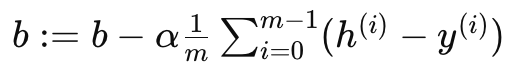
ここで、α は学習率、すなわち修正の歩幅を決定する魔法の杖です。重みに関するこの修正は、ライナー君が過去に踏みしめた土地(経験データ)と予測と実際のズレを基にして、各X印が地図上のどれだけ遠くにあるか、または近くにあるかを示すのに役立ちます。一方、バイアスの調整は、彼の全体的な進路を微調整し、宝へと直接導く役割を果たします。
これらの更新は、宝探しの途中でライナー君が集めた全ての手がかりと経験を統合し、彼の地図が実際の宝にどれだけ近づいているかを示すコスト関数の値を最小化するために用いられます。そうすることで、彼の地図は真実に一層近づき、未知の領域を探検する彼の勇気と知恵の旅は、最高の宝を見つける可能性を高めます。
「でも、これらの関数って実際にはどうやって使うの?」ライナー君が疑問に思ったとき、Pythonが彼の疑問に答えてくれます。例えば、ある花の種類を分類するためのシンプルなロジスティック回帰モデルを考えてみましょう。
from sklearn.datasets import load_iris # Irisのデータセットの呼び出しのため
from sklearn.model_selection import train_test_split
# ロジスティック回帰の実装に必要な関数を定義
# シグモイド関数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# コスト関数
def cost_function(h, y):
return (-y * np.log(h) - (1 - y) * np.log(1 - h)).mean()
# 勾配降下法の関数
def gradient_descent(X, h, y):
return np.dot(X.T, (h - y)) / y.shape[0]
# 予測関数
def predict(X, weights, bias):
return sigmoid(np.dot(X, weights) + bias)
# ロジスティック回帰関数
def logistic_regression(X, y, num_iter, learning_rate):
# 重みの初期化
weights = np.zeros(X.shape[1])
bias = 0
for i in range(num_iter):
z = np.dot(X, weights) + bias
h = sigmoid(z)
gradient = gradient_descent(X, h, y)
weights -= learning_rate * gradient
bias -= learning_rate * (h - y).mean()
# 1000回の繰り返し毎にコストを表示
if(i % 1000 == 0):
print(f'コスト: {cost_function(h, y)}')
return weights, bias
# Irisデータセットをロード
iris = load_iris()
X = iris.data
y = (iris.target == 2).astype(int)
# データセットを訓練セットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# モデルを訓練
num_iter = 10000
learning_rate = 0.1
weights, bias = logistic_regression(X_train, y_train, num_iter, learning_rate)
# テストセットで予測
predictions = predict(X_test, weights, bias) >= 0.5
print("予測:", predictions)
print("実際の値:", y_test)このコードは、アイリスのデータセットを用いて、ある花が特定の種類(ここでは3番目の種類)に属するかどうかを予測するモデルを訓練します。(次章では、scikit-learnを用いることにより簡単に実装できる方法も学びます)
ライナー君は目を輝かせながら、分類の魔法が現実の問題を解決する様子を見ています。「分類問題の解決にロジスティック回帰がどうしてピッタリなのか、少しは理解できたかな?」と彼は考えます。しかし、彼の冒険はまだまだこれから。性能の評価や、さらに複雑なデータセットへの適用など、新たな挑戦がライナー君を待ち受けています。
Pythonでライナー君の冒険をサポート
Pythonはロジスティック回帰モデルを構築する際の信頼できる相棒です。pandasでデータを整理し、NumPyで数値計算をこなし、scikit-learnでモデルを訓練することで、ライナー君はデータの分類問題を解決する力を手に入れることができます。
では、一連のステップを見てみましょう。
- データの準備: pandasを使ってデータを読み込み、探索します。欠けている値や不要な特徴量を処理し、データをモデルが理解できる形式に変換します。
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, roc_curve, roc_auc_score
import matplotlib.pyplot as plt
import seaborn as sns
# IrisデータセットをロードしてDataFrameを作成
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
# データを選択(バイナリ分類のために)
df_binary = df[df['target'].isin([0,1])] # 例えば、0と1のクラスだけを選択- 特徴量の選択: どの特徴量が予測に役立つかを決定します。相関係数や、特徴量の重要度を確認する手法を用いて、最も有益な特徴量を選択します。
- モデルの訓練: scikit-learnのLogisticRegressionクラスを使って、データを訓練セットとテストセットに分割し、モデルを訓練します。
X = df_binary.drop('target', axis=1)
y = df_binary['target']
# 訓練セットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルを訓練(multi_classとsolverオプションに注意)
model = LogisticRegression(solver='liblinear') # liblinearは小さいデータセットに適しています
model.fit(X_train, y_train)
# テストセットで予測
predictions = model.predict(X_test)- 結果の解釈: モデルのパフォーマンスは、単なる数字の羅列ではなく、ライナー君が冒険においてどれだけの進歩を遂げたかを示す貴重な指標です。テストセットでの予測を行うことにより、彼の訓練が実際の世界でどれだけ効果があるかを試験できます。
- 混同行列は、モデルが真の陽性をどれだけ正確に捉えたか、偽の陰性と誤って識別したかの数を示します。この行列を通じて、ライナー君は彼のモデルが実際に宝を見つけた回数(真陽性)と、見逃した宝の数(偽陰性)、宝と間違えた幻(偽陽性)の数を確認できます。
- ROC曲線は、さまざまな閾値でのモデルの感度と特異性のバランスを視覚的に表示し、モデルが宝の位置を識別するためにどれだけ効果的かを示します。この曲線は勇者の剣の切れ味を示すようなもので、曲線の下の面積(AUC)が大きいほど、モデルが宝探しの課題をうまく解決できることを意味します。
- ROC AUCスコアは、モデルがランダムな推測よりどれだけ優れているかを0から1までのスコアで示します。1に近いほど、モデルは完璧に近い予測をしていると言え、ライナー君の地図が現実の宝の位置に非常に近いことを意味します。
# 混同行列を作成
conf_matrix = confusion_matrix(y_test, predictions)
# 混同行列を表示
plt.figure(figsize=(10, 7)) # グラフのサイズを設定
sns.heatmap(conf_matrix, annot=True, fmt="d", cmap="Blues",
xticklabels=iris.target_names[0:2], yticklabels=iris.target_names[0:2])
plt.title('Confusion Matrix')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()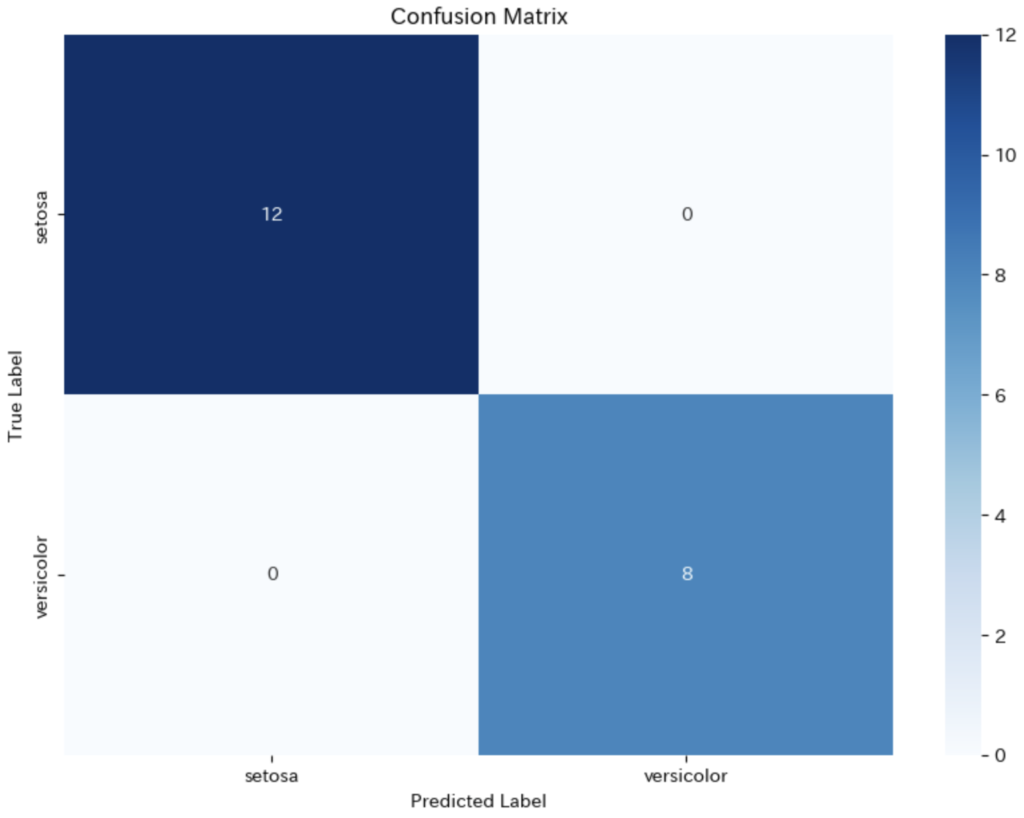
今回のモデルは全てのsetosaサンプルを正しく識別し、versicolorについても全て正確に予測しています。混同行列に誤分類(偽陽性や偽陰性)が含まれていないため、このテストセットに対するモデルの性能は非常に良いと言えます。
# ROC曲線のデータを計算(バイナリ分類のため)
fpr, tpr, thresholds = roc_curve(y_test, model.predict_proba(X_test)[:,1])
# ROC曲線のスコアを計算
roc_auc = roc_auc_score(y_test, model.predict_proba(X_test)[:,1])
# ROC曲線をプロット
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()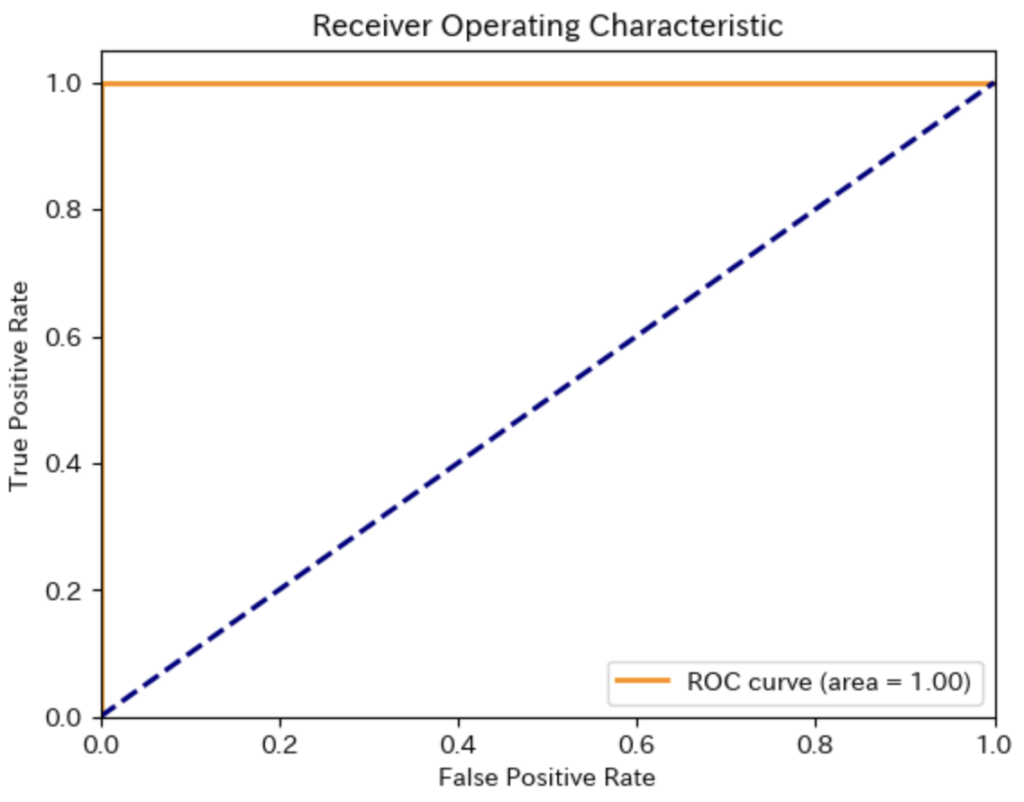
この図の曲線(オレンジ色)が左上隅に向かっていて、曲線の下の面積(AUC:Area Under the Curve)が1.00であることから、モデルが完璧な分類を行っていることを示しています。つまり、モデルは全てのポジティブケースを正しく識別し、ネガティブケースを誤ってポジティブと判定することがなかったことを意味します。
ライナー君はこれらのステップを踏んで、Pythonを使ってロジスティック回帰モデルを実装し、データの分類問題を解決する魔法を手に入れます。コードの各行が彼の剣となり、データの謎に立ち向かう彼の盾となるのです。
実践:分類のマジックを体験する
ここまでの旅で、ライナー君と一緒に数学の理論やPythonのコードを駆使してきました。しかし、真の冒険はこれからです。今度はあなたが主役となり、実際のデータセットを使ってロジスティック回帰モデルを構築し、本物の分類問題を解決します。
- データセットの選定: KaggleやUCI Machine Learning Repositoryなどのウェブサイトから、興味を引くデータセットを選びます。例えば、銀行のマーケティングデータセットで、顧客が定期預金を申し込むかどうかを予測してみましょう。
- データの探索と前処理: pandasを使ってデータを読み込み、基本統計量をチェックします。欠損値の処理やカテゴリ変数のエンコーディングなど、データをモデルが読み込める形に整えます。
- 特徴量エンジニアリング: どの変数が予測に寄与するかを検討し、必要に応じて新しい特徴量を作成します。
- モデルの構築と評価: scikit-learnを使ってロジスティック回帰モデルを訓練し、クロスバリデーションでモデルの堅牢性を評価します。
- 結果の解釈: 訓練されたモデルの性能を評価し、どの特徴量が予測に最も影響を与えているかを分析します。
この実践セクションを通じて、あなたはライナー君の冒険に自分の章を加え、データサイエンスの魔法使いとしてのスキルを磨き上げることができます。
まとめと次なる挑戦への道
私たちの勇敢な冒険者ライナー君は、ロジスティック回帰という強力な呪文を使いこなし、分類問題の謎を見事に解き明かしました。数値予測からカテゴリー分類へと、彼のデータ分析の旅は新たな地平を開きました。シグモイド関数の魔法と勾配降下法のコンパスを駆使して、彼はモデルを訓練し、データを分類する秘密を掴み取ったのです。
しかし、機械学習の世界は広大で、まだ探求すべき領域がたくさんあります。ロジスティック回帰は素晴らしい道具ですが、問題によっては過学習や汎化性能の低下という罠に落ちやすいこともあります。そこで登場するのが、正則化技術です。正則化は、モデルの複雑さにペナルティを課すことで、過学習を防ぎつつモデルの汎化能力を高める魔法のような手法です。
次なる挑戦は、この正則化技術を深く理解し、どのようにしてモデルの学習過程を改善するのかを学ぶことです。ライナー君は、過学習の嵐を乗り越え、より堅牢で信頼性の高いモデルを構築するために、この新たな知識を身につける必要があります。
ライナー君と共に、機械学習の次なる領域へと船出しましょう。正則化の技術は繊細で、そのバランスは微妙ですが、正しく使いこなすことで、モデルのパフォーマンスを大きく向上させることができます。次回のライナー君の冒険にご期待ください!


コメント