
こんにちは、こんぶちゃです!
CourseraのGoogleデータアナリティクス プロフェッショナル コースを受講しました。最終章のケーススタディ1問題 (How Does a Bike-Share Navigate Speedy Success?) をpythonで解いていきます。
- データアナリティクスに興味がある方
- Google データアナリティクス プロフェショナルコースを受けている方
- pythonのデータ可視化に興味がある方
Google データアナリティクスのコースでは、プログラミング言語としてはRを用いていますが、pythonの学習ブログを書いていますので、pythonを使って解析していきます。
まだまだ学習の身ですので、分析としては不足している部分も多々あるかと思いますが、その部分は同じ学習者として温かい気持ちで応援&ご助言頂けば嬉しいです。
では早速行ってみましょう!
補足)
Google データアナリティクスプロフェッショナルコースは、Googleが提供しているオンラインコースです。データ分析の考え方や進め方を段階的に学べました。私は非常に為になりました。また、スプレッドシート、SQL、R、Tableauの初歩も学べます。それと、合格証明書がオンラインで取得でき嬉しいです。
(私は、日本リスキリングコンソーシアムで行っていた無料のキャンペーンで受講できお得でした)
今回の問題:How Does a Bike-Share Navigate Speedy Success?
0. 背景 & シナリオ
2016年にスタートしたCyclistic (架空会社) は、自転車シェアプログラムを提供しています。5,824台の自転車、シカゴ全体に692のステーションが展開されています。
マーケティングディレクターは、会社の将来の成功は年間会員数の最大化することに依存していると考えています。アナリティクスチームは、カジュアルライダーと年間メンバーがCyclisticの自転車の使用方法がどのように異なるかを理解したいと考えています。これらの洞察から、チームは新しいマーケティング戦略を設計し、カジュアルライダーを年間メンバーにする計画です。しかし、まず最初に、Cyclisticの役員はチームの提案を承認する必要があるため、説得力のあるデータ洞察とプロのデータ可視化を示す必要があります。
* 最終課題のケーススタディ1の問題文の抜粋
データ解析の流れ (ワークフロー)
データアナリティクスコースで学習した下記の流れで考えていきます。
- 問いかけ
- 準備
- 処理
- 分析
- 共有
- 行動
1. 問いかけ
間違った問いかけをしてしまうと、この後のプロセスが全て無駄になります。その他、正しい問いかけをすることが何より重要です。
正しい問いかけに導くためのガイドクエスチョンとキータスクの指示に従いながら進めます。
ガイドクエスチョン(下線部)
- 問題解決しようとしている課題は何ですか?
- カジュアルライダーと年間メンバーがCyclisticの自転車の使用方法においてどのように異なるかを明確にする
- あなたの洞察はビジネスの意思決定にどのように影響しますか?
- わたしのインサイトが新しいマーケティングの方向性に影響を与える
キータスク(下線部)
- 事業タスクの特定
* 事業タスクとは、データ分析で解決できる疑問または課題- カジュアルライダーと年間メンバーがCyclisticの自転車の使用方法においてどのように異なるかを明確にし、それに基づいて新しいマーケティング手法を開発する
- 主要なステークホルダーを考慮する
- 主要なステークホルダーとしてCyclisticのエグゼクティブチームを考慮する
上記を踏まえ、問いかけを下記に定義します。
問いかけ:
Cyclisticのエグゼクティブチームに対して、カジュアルライダーと年間メンバーがCyclisticの自転車の使用方法においてどのように異なるかを明確にする。
2. 準備
ここで特に重要なのがデータがROCCCであるかを確認することです。
ROCCCとは、下記の頭文字をつなげた造語です(参考ページ)
- Reliable(信頼性)
- Original(独自性)
- Comprehensive(包括的である)
- Current(最新)
- Cited(引用)
今回は、問題で指示されたデータを使うため、ROCCCが満たされている前提で進めます。一般的には、データの取得の仕方にバイアスがかかっていたり、包括的ではなかったりとデータの確認に時間を割く必要があります。
早速、データの取り込みをしていきます。今回は、Google Colaboratory を用いて解析を進めていきます。ダウンロードしたファイルは、Google Driveに保存しています(ZipファイルをCSVファイルに解凍済み)
# Google Drive と Google Colaboratoryの連結
from google.colab import drive
drive.mount('/content/drive')上記を実行すると、連携していいかのポップアップが出てきます。指示に従って、連携を行います。
ライブラリーをインポートします。
# pandasライブラリをpdとしてインポート
import pandas as pd
# osライブラリをインポート
import os
# seabornライブラリをsnsとしてインポート
import seaborn as sns
# matplotlib.pyplotライブラリをpltとしてインポート
import matplotlib.pyplot as plt
# グラフをノートブック内に表示するためのマジックコマンド
%matplotlib inline今回扱うデータは、2021年1月〜12月のデータになります。すべてのデータを扱うと容量が多く確認時間が長くかかります。まずは、1月分のデータを取り込みデータの取り込み、構造の確認を行っていきます。
CSVファイルは、My Driveの直下にCSV_Cyclistic_2021のフォルダを作成し、その下にCSVファイルを保存しています。
# Pandasライブラリを使用してCSVファイルを読み込み、データフレームに格納
df = pd.read_csv("drive/My Drive/CSV_Cyclistic_2021/202101-divvy-tripdata.csv")
# データフレームの形状(行数と列数)を表示
print(f'Shape: {df.shape}')
# データフレームの最初のいくつかの行を表示
df.head()
データの整合性確認のため、データ型の確認、欠損値の確認、重複の確認を行っています。
まずは、データ型と欠損値(非欠損値)の確認を行います。
pythonには、非常に優れたコマンドがいくつもあります。その中の一つの info() を用います。
df.info()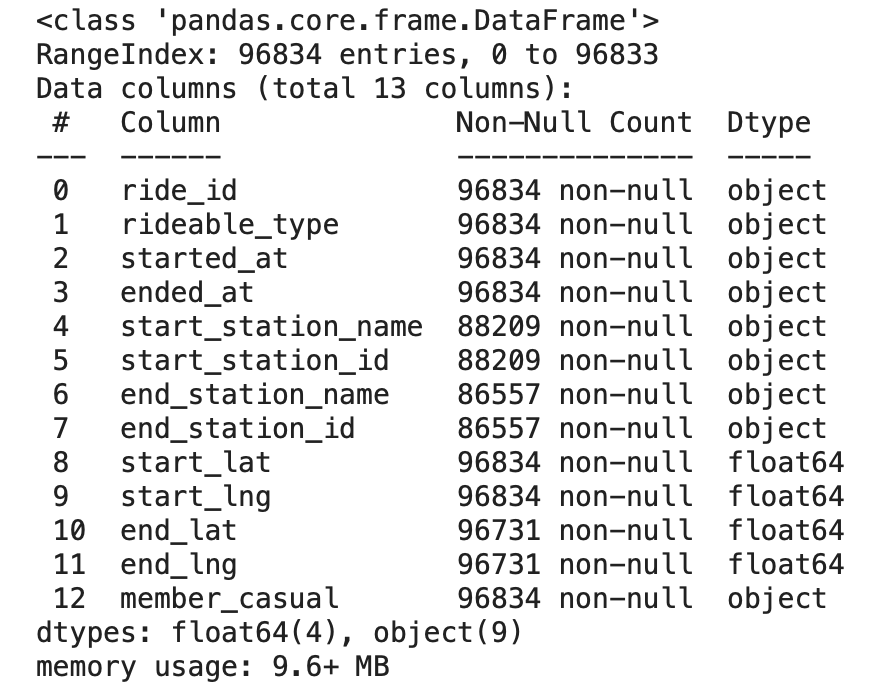
上記の内容をまとめて、内容の補足を入れると下記になります。
| カラム | 内容 | 非欠損値数 | データタイプ |
|---|---|---|---|
| ride_id | ライドID | 96834 | object |
| rideable_type | ライド可能な自転車のタイプ | 96834 | object |
| started_at | ライドの開始日時 | 96834 | object |
| ended_at | ライドの終了日時 | 96834 | object |
| start_station_name | 開始駅の名称 | 88209 | object |
| start_station_id | 開始駅のID | 88209 | object |
| end_station_name | 終了駅の名称 | 86557 | object |
| end_station_id | 終了駅のID | 86557 | object |
| start_lat | 開始駅の緯度 | 96834 | float64 |
| start_lng | 開始駅の経度 | 96834 | float64 |
| end_lat | 終了駅の緯度 | 96731 | float64 |
| end_lng | 終了駅の経度 | 96731 | float64 |
| member_casual | メンバーかカジュアルかのステータス | 96834 | object |
started_at と ended_at は日付データですが、object型になっていることがわかります。次の処理で変換を行なっていきます。
欠損値に関しては、主要項目に関しては欠損値がなく、駅の名称の欠損値が見られるが9割のデータは存在していることがわかります。駅の名称での分析を行う必要が出てきた場合に欠損値の扱いを考えたいと思います。
次に重複があるかを確認していきます。
# データフレーム df に対して重複を確認
duplicates = df[df.duplicated()]
# 重複があるかどうかを確認
if duplicates.empty:
print("重複はありません。")
else:
print("重複があります。")
print(duplicates)
# 出力: 重複はありません。データの整合性が確認できましたので、次の重複がありませんでしたので、次の処理のプロセスに進ます。
3. 処理
データのクリーニングを行い、データの加工も行っていきます。
まず、先ほど見つけた started_at と ended_at のデータ型が object になっていたため、日付型に変更していきます。
# 日付の型変換
# 'started_at' と 'ended_at' 列のデータ型を日付型に変換
cols = ['started_at', 'ended_at']
for col in cols:
df[col] = pd.to_datetime(df[col])
# 変換後のデータ型と欠損値の情報を表示
df[cols].info()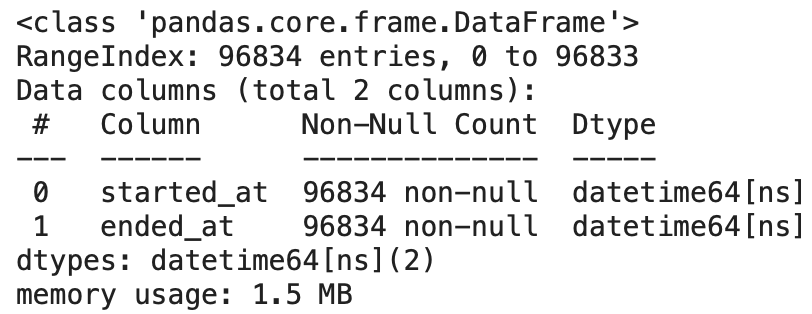
object型 → datetime型に変更されています。
次に、異常値を確認していきます。started_atに対して、ended_atは必ず遅くないといけないので、時間の逆転(同時も含む)が起こっていないかを確認しています。
# 'ended_at' が 'started_at' 以下の行を選択
# つまり、終了時刻が開始時刻以下の場合のデータを抽出
df[df['ended_at'] <= df['started_at']]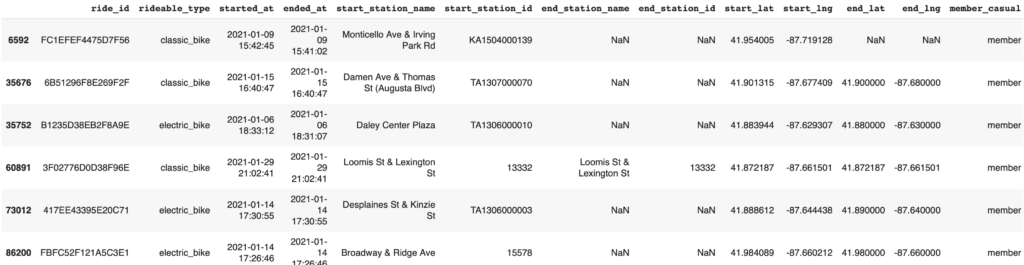
異常値が含まれていることがわかったため、これらのデータを除外します。
# データの整合性を確保するため、'ended_at' が 'started_at' よりも前の行を削除
# 削除前の行数を保存しておき、削除後の行数との差分を表示
before = df.shape[0]
df = df[df['ended_at'] > df['started_at']]
print(f'Number of deletions: {before - df.shape[0]}')
#出力 Number of deletions: 6上記の6行分削除されています。
次にカテゴリカルデータ(質的データ:カテゴリーや属性を表すデータ)の確認を行っていきます。ユニークな値の出現回数をカウントすることにより、エラー値がないかを確認していきます。
# 特定の列における各要素の出現回数を表示するループ処理
# 'rideable_type', 'start_station_name', 'end_station_name', 'member_casual' 列について、各要素の出現回数を表示
cols = ['rideable_type', 'start_station_name', 'end_station_name', 'member_casual']
for col in cols:
print(f'{col} :')
display(df[col].value_counts())
print('-----------------------')異常値がないことがわかります。
データのクリーニングができましたので、次にデータの加工を行っていきます。
データの加工は次の2つのことを行っていきます。
- 乗車時間の算出
- 月と曜日の抽出
まず、乗車時間の算出ですが、各行に対して次の式で求めます
乗車時間 = ended_at – started_as
# 乗車時間を算出
df['ride_length'] = df['ended_at'] - df['started_at']
# 'ride_length'の秒数を取得
df['ride_length_seconds'] = df['ride_length'].dt.total_seconds()
# 'ride_length_seconds'を分に変換
df['ride_length_minutes'] = df['ride_length_seconds'] / 60* 今後扱いやすいように秒数と分数表示も追加しています
次に、started_at の月と曜日の抽出を行います
# 'started_at'から月を抽出して新しい列を作成
df['month'] = df['started_at'].dt.month
# 曜日を取得して新しい列に追加 (0(月曜日)から6(日曜日))
df['weekday'] = df['started_at'].dt.dayofweek
df.head()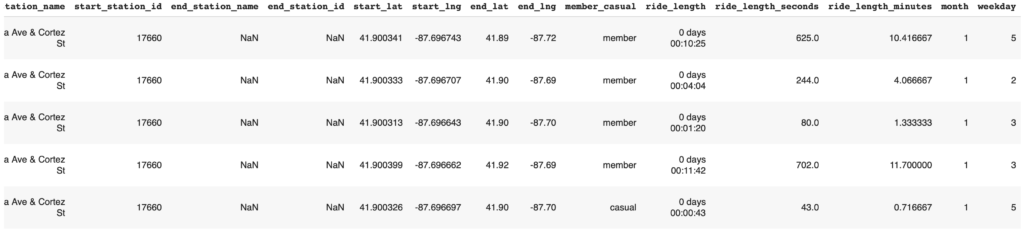
右側に、ride_length, ride_length_seconds, ride_length_minutes, month, weekday が追加されています。
データクリーニング、データ加工ができましたので、次の分析にいきます。
4. 分析
上記までは1月分のデータ確認してきましたが、ここからは12月分のデータを読み込み解析を行なっています。
* 全データを使うと実行時間が長くなってしまうため、1月分のみで傾向性を確認してから、全データで解析に進んだ方が検討時間が短く済みます。自分もこのやり方を実施しています。
# フォルダにあるcsvファイルを取り込み結合
# フォルダのパス
folder_path = 'drive/My Drive/CSV_Cyclistic_2021/'
# フォルダ内のCSVファイル名を取得
csv_files = [f for f in os.listdir(folder_path) if f.endswith('.csv')]
# すべてのCSVファイルを1つのデータフレームにまとめる
dfs = []
for csv_file in csv_files:
file_path = os.path.join(folder_path, csv_file)
_df = pd.read_csv(file_path)
dfs.append(_df)
# データフレームを結合
df = pd.concat(dfs, ignore_index=True)
print(f'Shape: {df.shape}')
df.head()数値データの統計データを確認します。
# 数値データに関する基本統計量を表示
df.describe()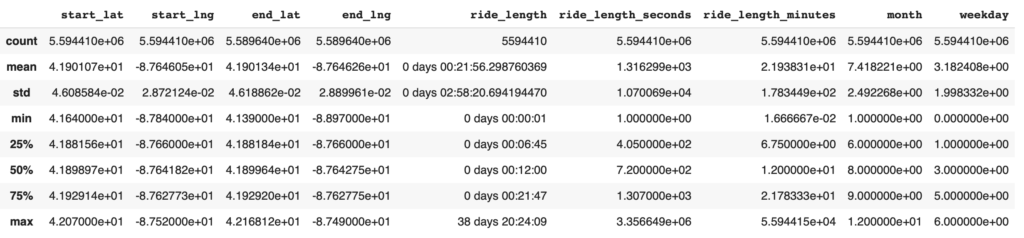
ride_lengthを見ると、75%時の値が21分に対して、max値が38日と大きく離れていることがわかります。このデータを外れ値として扱うかを確認するため、箱ひげ図で確認していきます。
# 外れ値の確認 (x軸を日数表示に変更)
# ride_lengthではグラフ化できないため、秒数変換したride_length_secondsを用いる
plt.figure(figsize=(10, 4))
sns.boxplot(x=df['ride_length_seconds'] / (60*60*24)) # 秒を日に変換
plt.title('Boxplot of Ride Length (Days)')
plt.xlabel('Ride Length (Days)')
plt.show()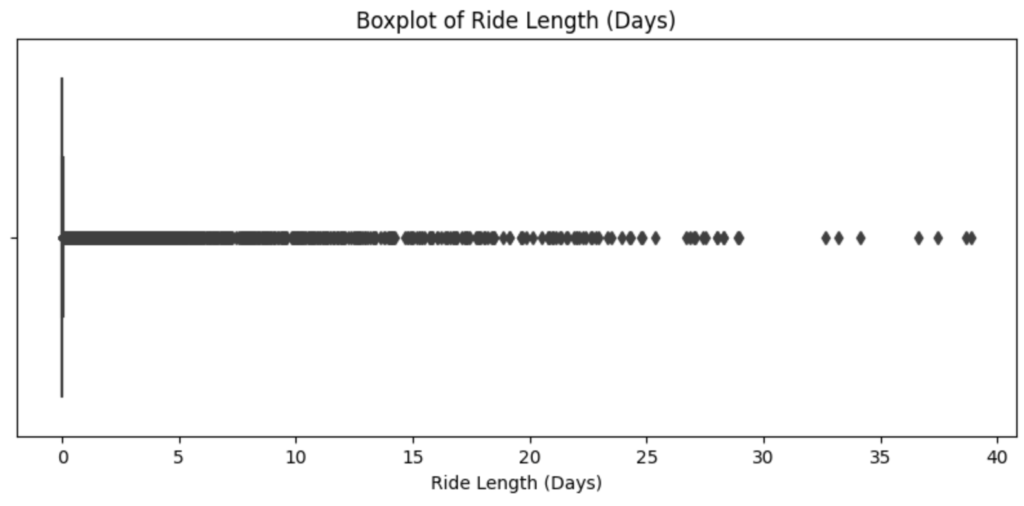
どこから外れ値として扱うか難しいところではありますが、今回は乗車時間が30日以上のデータを外れ値として扱っていきます。
# DataFrameの初期行数を保存
before = df.shape[0]
# ride_length_secondsが5日以上の行をフィルタリング
df = df[df['ride_length_seconds'] < 60 * 60 * 24 * 30]
# 削除された行の数を計算して表示
print(f'削除された行数: {before - df.shape[0]}')
# 出力: Number of deletions: 7ここで、初めに設定した問いかけを再度記載します。
Cyclisticのエグゼクティブチームに対して、カジュアルライダーと年間メンバーがCyclisticの自転車の使用方法においてどのように異なるかを明確にする。
実際にデータを扱っていくと、データのクリーニングや処理のことに集中してしまい、当初の目的を忘れてしまうことがあります。そのため、度々問いかけに戻るようにしています。
カジュアルライダーと年間メンバーの乗車時間の違いがあるかを比較します。seabornの棒グラフを用いることにより、事前に集計せずに比較することができます。
# プロット領域のサイズを指定
plt.figure(figsize=(6, 4))
# seabornのbarplotを使用してカテゴリごとの棒グラフを描画
sns.barplot(x=df['member_casual'], y=df['ride_length_minutes'])
# グラフのタイトルと軸ラベルを指定
plt.title('Barplot of Ride Length (Minutes)')
plt.ylabel('Ride Length (Minutes)')
# グラフを表示
plt.show()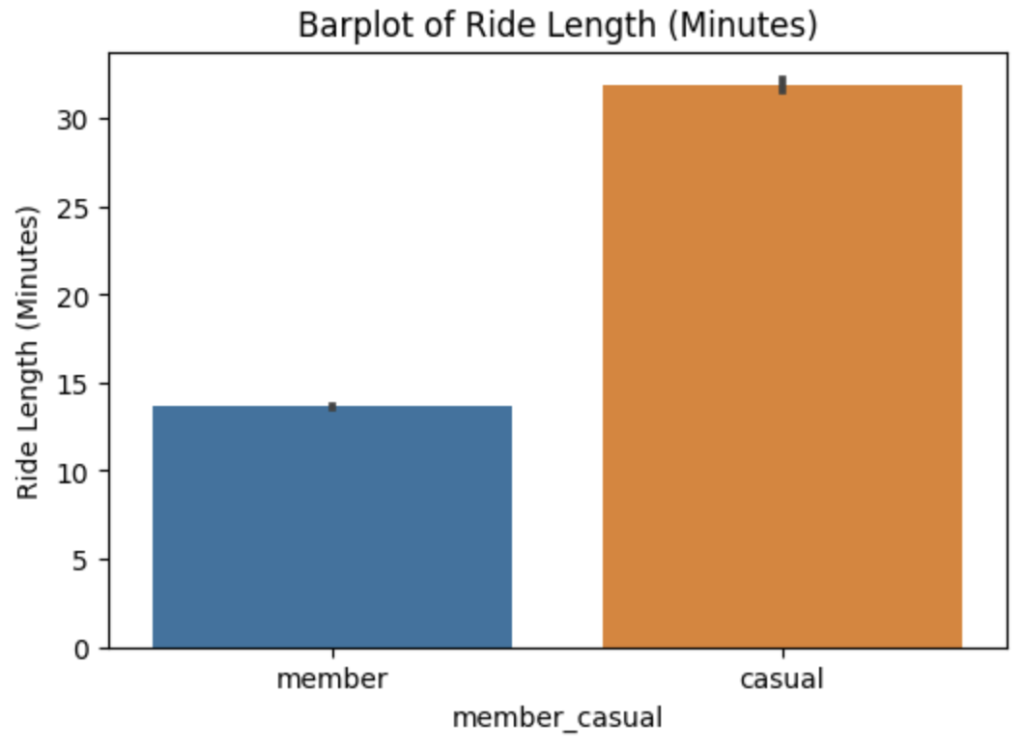
カジュアルライダーの平均乗車時間は、年間メンバーの2倍以上になっています。
次にメンバータイプごとの乗車回数を調べます。
# メンバータイプごとの乗車回数をカウント
ride_counts = df['member_casual'].value_counts()
# seabornのbarplotを使用してカテゴリごとの棒グラフを描画
sns.barplot(x=ride_counts.index, y=ride_counts.values)
# グラフのタイトルと軸ラベルを指定
plt.title('Barplot of Ride Counts')
plt.ylabel('Ride Counts')
# グラフを表示
plt.show()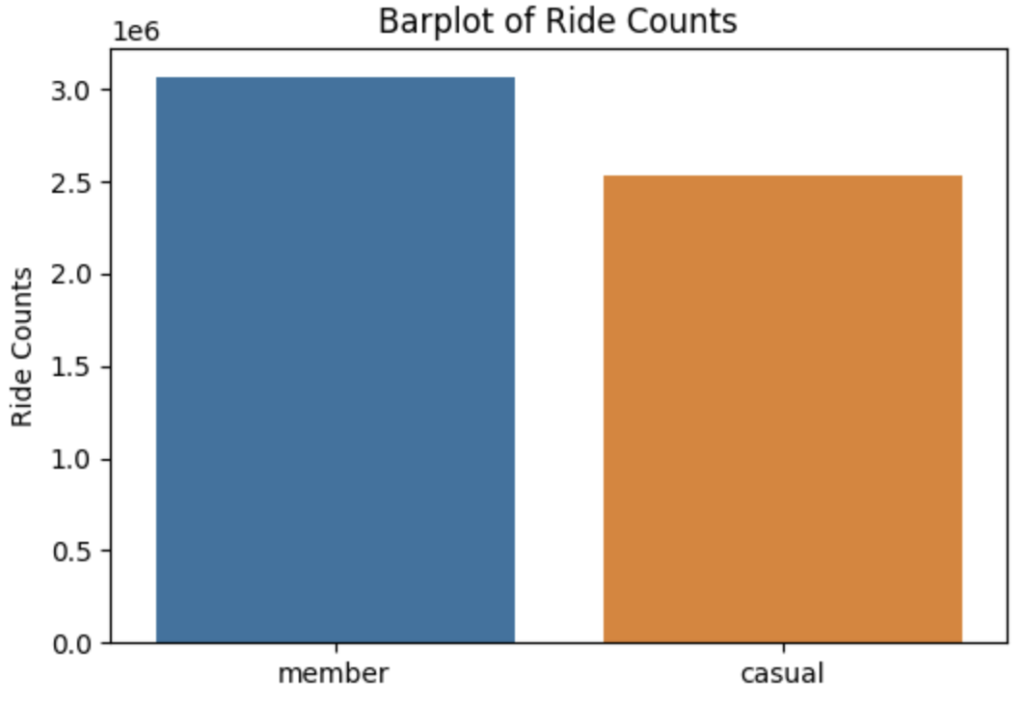
上記より、カジュアルメンバーは、年間メンバーに比べ平均乗車時間は2倍以上長く、乗車回数も年間メンバーの8割の利用があることがわかります。
次にカジュアルメンバーと年間メンバーが曜日毎に乗車時間と回数の傾向性を調べます。
曜日毎の平均乗車時間の傾向性)
# 曜日の順序を定義
day_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
# DataFrameからヒートマップを作成
heatmap_data = df.pivot_table(columns='weekday', index='member_casual', values='ride_length_minutes', aggfunc='mean')
# ヒートマップをプロット
plt.figure(figsize=(12, 5))
sns.heatmap(heatmap_data, cmap='coolwarm', annot=True, fmt=".0f", cbar_kws={'label': 'Average Ride Length (seconds)'})
# 曜日の順序を設定
plt.xticks(ticks=[i + 0.5 for i in range(7)], labels=day_order, rotation=0)
# グラフのタイトルと軸ラベル
plt.title('Average Ride Length (Minutes) by Day of Week and User Type')
plt.xlabel('Day of Week')
plt.ylabel('User Type')
plt.show()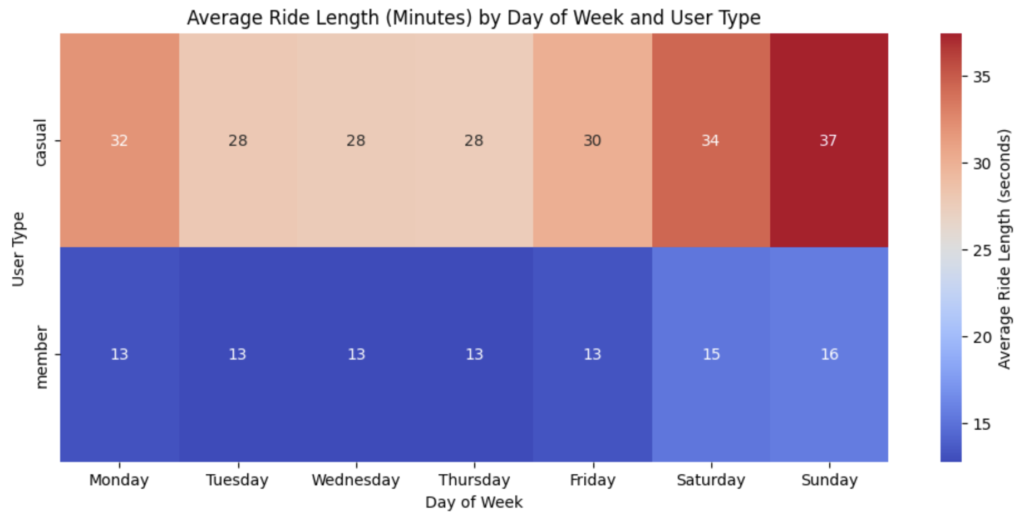
カジュアルメンバーは、どの曜日においても年間メンバーの倍以上乗車していることがわかります。特に日曜日に差が顕著になっています。次に乗車時間を確認していきます。
曜日毎の乗車回数)
# 曜日ごとの出現回数をクロス集計
cross_tab = pd.crosstab(df['weekday'], df['member_casual'])
display(cross_tab)
# 積み上げグラフを作成
plt.figure(figsize=(10, 4))
sns.barplot(x=cross_tab.index, y=cross_tab['casual'], color='#ff7f0e', label='Casual')
sns.barplot(x=cross_tab.index, y=cross_tab['member'], color='#1f77b4', label='Member', bottom=cross_tab['casual'])
# グラフのタイトルと軸ラベル
plt.title('Ride Count by Day of Week and User Type')
plt.xlabel('Day of Week')
plt.ylabel('Ride Count')
# 曜日のラベルを設定
plt.xticks(range(7), ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'])
# 凡例を表示
plt.legend(title='User Type')
# グラフを表示
plt.show()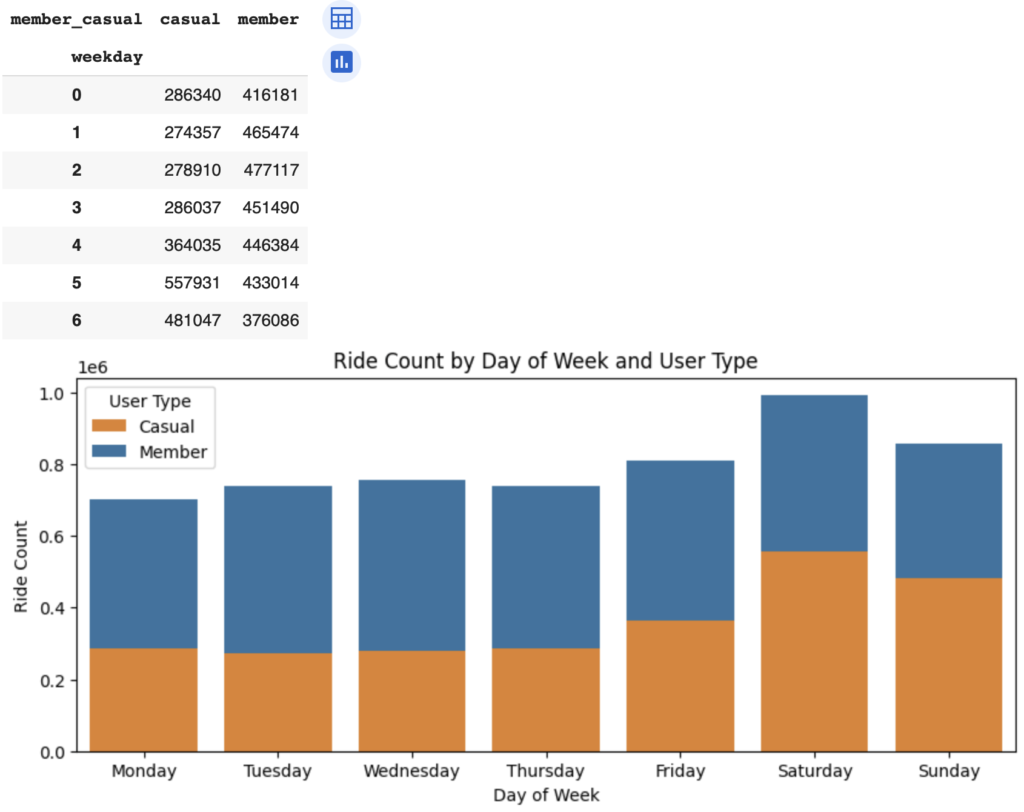
平日は、年間メンバーの方が利用回数が多いが、週末はカジュアルメンバーの利用回数が多いことがわかります。両方のメンバーを含めた利用回数は、土曜日が一番多いこともわかります。
次に自転車のタイプの違いがカジュアルメンバーと年間メンバーで傾向性が異なるかを確認していきます。
ユーザータイプに対する自転車タイプ毎の平均乗車時間)
# DataFrameからヒートマップを作成
heatmap_data = df.pivot_table(columns='rideable_type', index='member_casual', values='ride_length_minutes', aggfunc='mean')
# ヒートマップをプロット
plt.figure(figsize=(6, 5))
sns.heatmap(heatmap_data, cmap='coolwarm', annot=True, fmt=".0f", cbar_kws={'label': 'Average Ride Length (minutes)'})
# グラフのタイトルと軸ラベル
plt.title('Average Ride Length (Minutes) by Rideable Type and User Type')
plt.xlabel('Rideable Type')
plt.ylabel('User Type')
plt.show()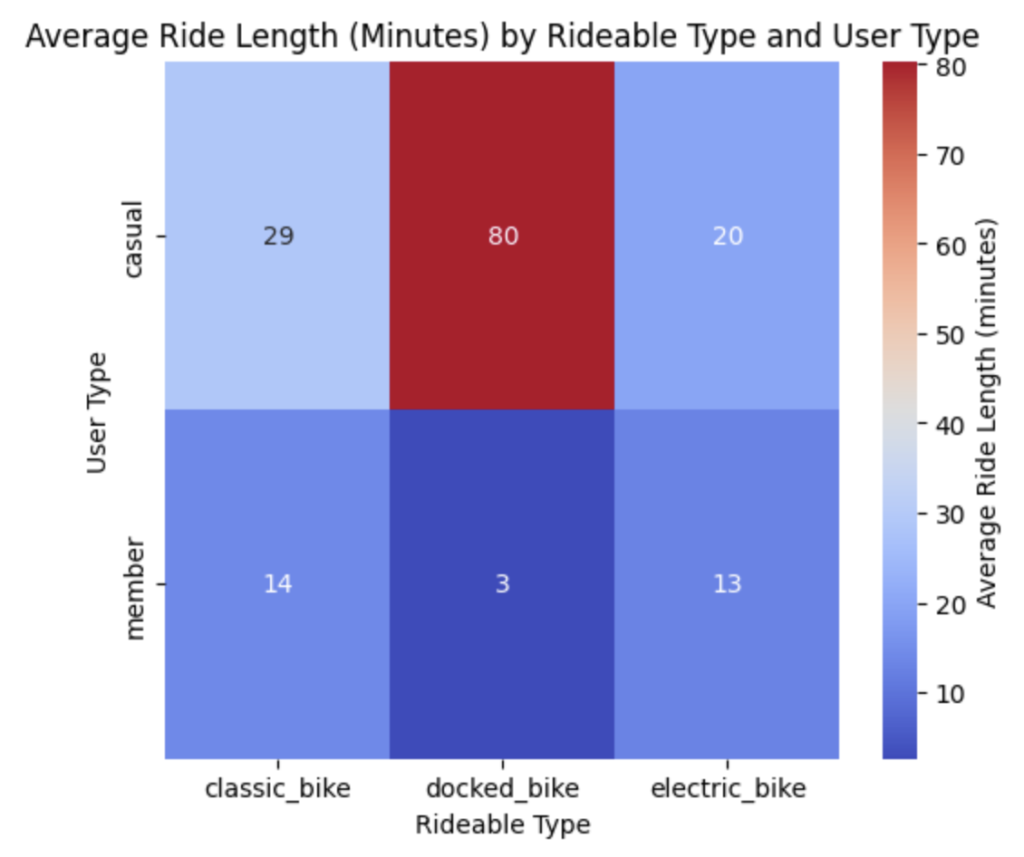
Docked bikeはほぼカジュアルメンバーだけの利用であり、かつ、平均乗車時間も飛び抜けて長くなっています。次に自転車タイプ毎の平均乗車回数を求めます。
# 自転車タイプごとの出現回数をクロス集計
cross_tab = pd.crosstab(df['rideable_type'], df['member_casual'])
display(cross_tab)
# 積み上げグラフを作成
plt.figure(figsize=(10, 4))
sns.barplot(x=cross_tab.index, y=cross_tab['casual'], color='#ff7f0e', label='Casual')
sns.barplot(x=cross_tab.index, y=cross_tab['member'], color='#1f77b4', label='Member', bottom=cross_tab['casual'])
# グラフのタイトルと軸ラベル
plt.title('Ride Count by rideable_type and User Type')
plt.xlabel('Rideable Type')
plt.ylabel('Ride Count')
# 凡例を表示
plt.legend(title='User Type')
# グラフを表示
plt.show()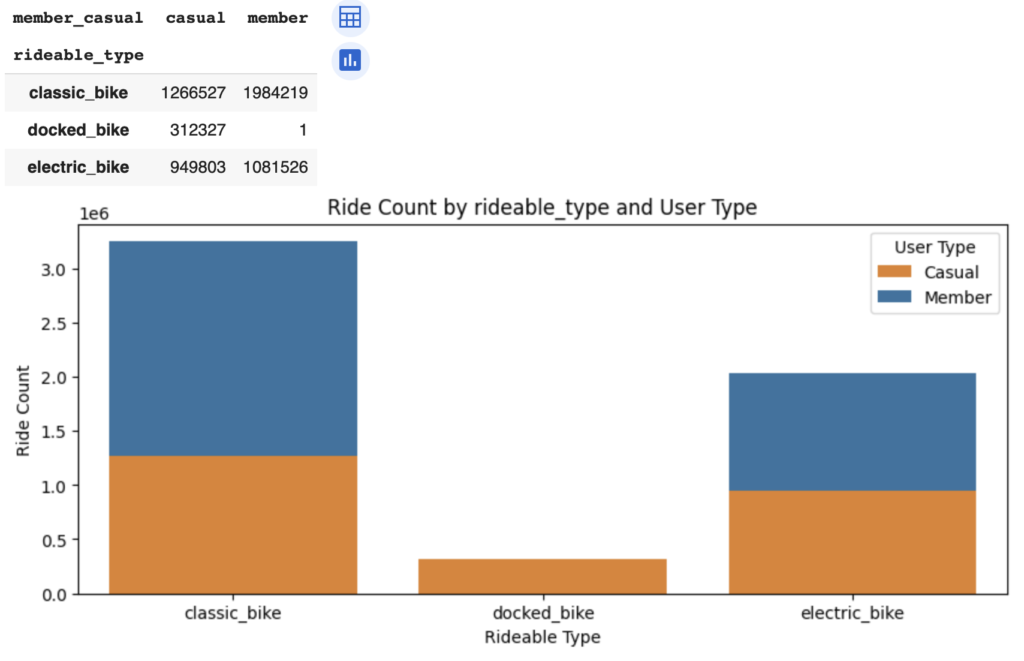
docked bikeは、ほぼカジュアルメンバーの利用者だけになっています。年間メンバーは、クラシックバイクを好む傾向があることがわかります。
次に月毎におけるカジュアルメンバーと年間メンバーの推移を確認していきます。
# seabornのhistplotを使用して月ごとの乗車回数を積み上げヒストグラムとして描画
sns.histplot(data=df, x='month', hue='member_casual', multiple='stack', binwidth=1)
# グラフのタイトルと軸ラベルを指定
plt.title('Stacked Histogram of Ride Counts by Month and Member Type')
plt.xlabel('Month')
plt.ylabel('Ride Counts')
# グラフを表示
plt.show()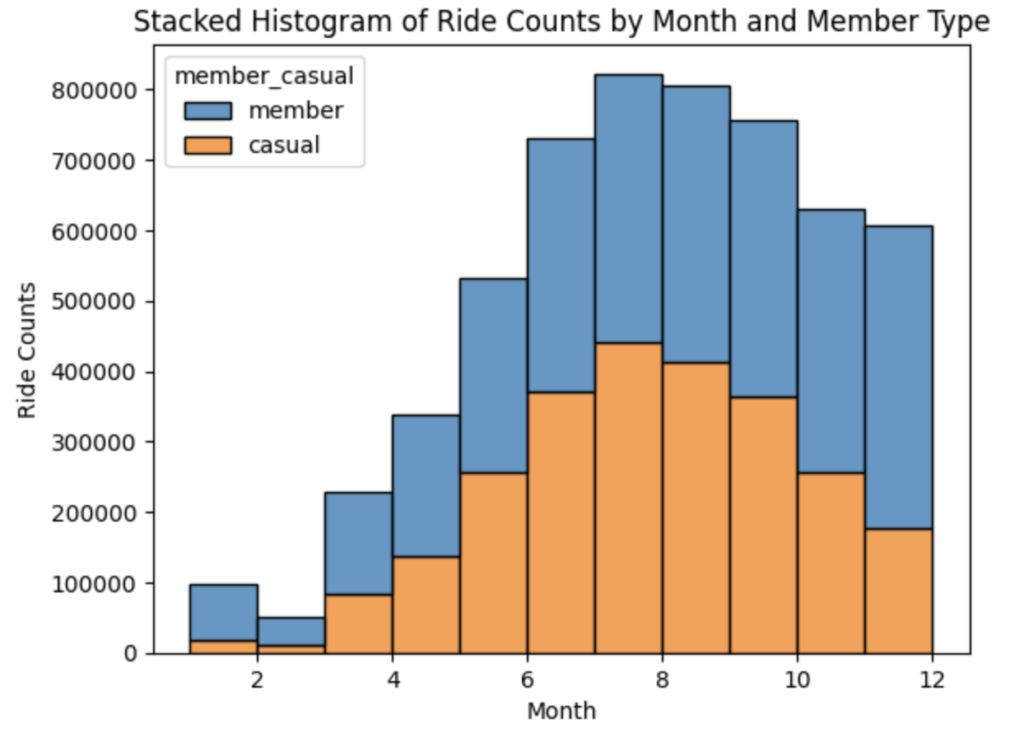
上記のグラフから下記のことが読み取れます。
- 夏場(6月〜9月)に利用者が増加している
- 2021年3月くらいから利用者が拡大している
- 後半にかけてカジュアルメンバーの比率が高くなってきている
分析が終わったため、次の共有に移っていきます。
5. 共有
共有に関しては、視覚化を行なったり、プレゼン化を行なったりします。視覚化に関しては、分析段階で視覚化も行いながら実施してきたため、ここでは省略します。
また、プレゼン化もブログを通じて発信しているため、こちらも省略します。
6. 行動
以上の分析結果からの結論を導きます。
カジュアルメンバーと年間メンバーの違い
- カジュアルメンバーは週末利用が多い傾向があります
- カジュアルメンバーの方が乗車時間が長い傾向があります
- 年間メンバーはクラシックバイクを好む傾向があります
カジュアルメンバーを年間メンバーにするためのアイデア
- カジュアルメンバーの利用が多い週末に年間メンバー登録キャンペーンを打ち出す
- 週末利用に特化した新たな会員区分を設ける
- カジュアルメンバーの利用比率が高い電気自転車を代替的にアピールする
感想
先月から取り組みをしていたGoogle Data Analytics Professional Certification の資格を取得することができました !^^!
データ解析を体系的に学ぶことができ、非常にためになりました。スプレッドシート, R, SQL, Tableauなどのツールやプログラミングの触りも学ぶことができます。
今回は、最終課題の一つをこのブログで取り上げてみました。データ解析からAct (行動) に結びつけることが難しかったので、問いかけ、準備、処理、分析、共有、行動 のフローがすぐに出てくるまで練習を行なっていきたいです。
来月もCase Study 2の課題を取り上げていきます。乞うご期待ください。


コメント