
こんにちは、こんぶちゃです!
KaggleのHouse Prices (住宅価格の予測) をchatGPTを用いて解いて行きます。
- データサイエンスに興味がある方
- Kaggleを見よう見まねで解いてみたが、内容がピンとこない方
- エクセルで扱えない大量のデータの扱いに困っている方
以前に自身で解析を行いましたが(こちらのページ参照)、chatGPTの Data Analysis 機能がどのくらい使えるか検証を行なって行きます。
では早速行ってみましょう!
今回の問題:House Prices – Advanced Regression Techniques
House Prices – Advanced Regression Techniques
データ解析の流れ (ワークフロー)
chatGPTにデータを渡す。これだけです。
分析方法含めchatGPTにお任せです。
1. 準備
KaggleのHouse Pricesのページから与えられた4つのデータをダウンロードします。
- data_description.txt ・・・ データの説明
- train.csv ・・・ トレーニングデータ
- test.csv ・・・ テストデータ
- sample_submission.csv ・・・ 提出の形
chatGPTは、GTPsのData Analysisを用います。これは、Data Analysis用に既にチューニングされているchatGPTです。OpenAIから提供いただいているchatGPT4の標準に備わっています。

今回データの入力とコードインタプリター機能が必要なため、有料のchatGPT4を用います。
2. プロンプト
準備が整いましたので、早速プロンプトを生成して行きます。今回は丸投げでどこまで対応してくれるかを知りたいため、最低限のプロンプトにしています。
* 段階的(ステップバイステップ)と入れると精度が上がる検証結果があるため、この言葉は追加しています。

(データを添付し忘れたため、次のプロンプトでデータだけ添付しています)
3. 実行
chatGPTから、今回のプロセスフローと渡したデータの確認を行なっていただけます。




ここまで一度に出力されます。しかも数分で。これには驚きました。今回は、グラフ化などのお願いをしていなかったので、グラフ化を入れたりするのもいいのではないかと思います。
「続けて下さい」とお願いしました。



自動でコードを作成して、実行 -> エラーになったら再度自ら修正して実行! AI の進化を感じます。しかも、途中のエラーなどを含めても、ここまで10分足らずで実行してくれます。
* 途中、急にchatGPTが止まることもありましたが、そういう場合は画面を更新し、再度「続けて下さい」と入力すると途中から進めてくれます。
私が自分で似たような処理を行なったときは、数時間かかっていました。。。
今回の処理内容を実際にKaggleに提出するため、読み込みから出力までのコードを作ってもらいました。ただし、コードをまとめた際に動くかどうか心配がありましたので、動作チェックもお願いしています。
「読み込みから出力までのコードをまとめて。動作検証を行なって。問題なければ、そのコードを出力して」
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np
# ファイルパス
train_file_path = '/mnt/data/train.csv'
test_file_path = '/mnt/data/test.csv'
# データの読み込み
train_data = pd.read_csv(train_file_path)
test_data = pd.read_csv(test_file_path)
# 欠損値が多い特徴を除外
missing_train = train_data.isnull().sum()
features_to_drop = missing_train[missing_train > (0.15 * len(train_data))].index
train_data_cleaned = train_data.drop(columns=features_to_drop)
test_data_cleaned = test_data.drop(columns=features_to_drop)
# 残りの欠損値を補完
for column in train_data_cleaned.columns:
if train_data_cleaned[column].isnull().sum() > 0:
if train_data_cleaned[column].dtype == 'object':
train_data_cleaned[column] = train_data_cleaned[column].fillna(train_data_cleaned[column].mode()[0])
else:
train_data_cleaned[column] = train_data_cleaned[column].fillna(train_data_cleaned[column].median())
for column in test_data_cleaned.columns:
if test_data_cleaned[column].isnull().sum() > 0:
if test_data_cleaned[column].dtype == 'object':
test_data_cleaned[column] = test_data_cleaned[column].fillna(test_data_cleaned[column].mode()[0])
else:
test_data_cleaned[column] = test_data_cleaned[column].fillna(test_data_cleaned[column].median())
# ワンホットエンコーディング
train_features = pd.get_dummies(train_data_cleaned)
test_features = pd.get_dummies(test_data_cleaned)
# 共通の特徴に基づいてデータセットを再構築
common_features = train_features.columns.intersection(test_features.columns)
X_train = train_features[common_features].drop(['SalePrice'], axis=1)
X_test = test_features[common_features].drop(['Id'], axis=1)
y = train_data['SalePrice']
# ランダムフォレストモデルのトレーニング
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y)
# テストデータに対する予測
test_predictions = rf_model.predict(X_test)
# 提出用ファイルの作成
submission = pd.DataFrame({
'Id': test_data['Id'],
'SalePrice': test_predictions
})
# 提出用ファイルの保存(例:submission.csvとして保存)
submission.to_csv('/mnt/data/submission.csv', index=False)読み込み先と提出部分をKaggle用に変換して、提出を行いました。

結果は、0.147でした。順位で言うと約2400/4621位です。約50%近くまで来ています。十分足らずを考えるとすごいことだと思います。
4. 検証
今回のコードを確認して行きます。
前処理としては下記のことを実施してくれています。
- 欠損値が15%以上ある項目の削除
- 欠損値を最頻値での補完
- ワンホットエンコーディングによるカテゴリーデータの数字化
今回のデータセットだと、欠損値と無しが混ざっていますが、そのデータの理解まではできてはいませんでした。例えば、PoolQCのデータ無しは、プール自体がないためクオリティーデータが欠損値になっていると考えれますが、項目毎削除されています。
欠損値の穴埋めでは、意味を理解して0で穴埋めをするべきところがありますが、全て最頻値の穴埋めになっています。例:GarageCars は、ないため欠損値になっているため、0にすべきです。
ワンホットエンコーディングもいいですが、品質などは順番に意味があるため、私はラベルエンコーディングとワンホットエンコーディングの二つを行いました。
上記以外で私が行なった前処理は下記です
- 異常値の削除 ・・・ GrLivAreaの異常値を削除
- 対数化
異常値に関しては、GrLivArea – SalePriceにおいて異常値を発見し削除しました。
SalePriceが歪度があるため、対数化することにより歪度を正しくすることができます。今回の予測においては、非常に重要な部分でありますので、この前処理は実施して欲しかったところです。
以上のことから、前処理に関してはグラフの表示の依頼をし、項目の意味の理解を共に考えながら、処理するのがいいのではないかと思います。
GrLivArea – SalePriceの散布図で確かめてみました
「GrLivArea – SalePriceの散布図を作って」
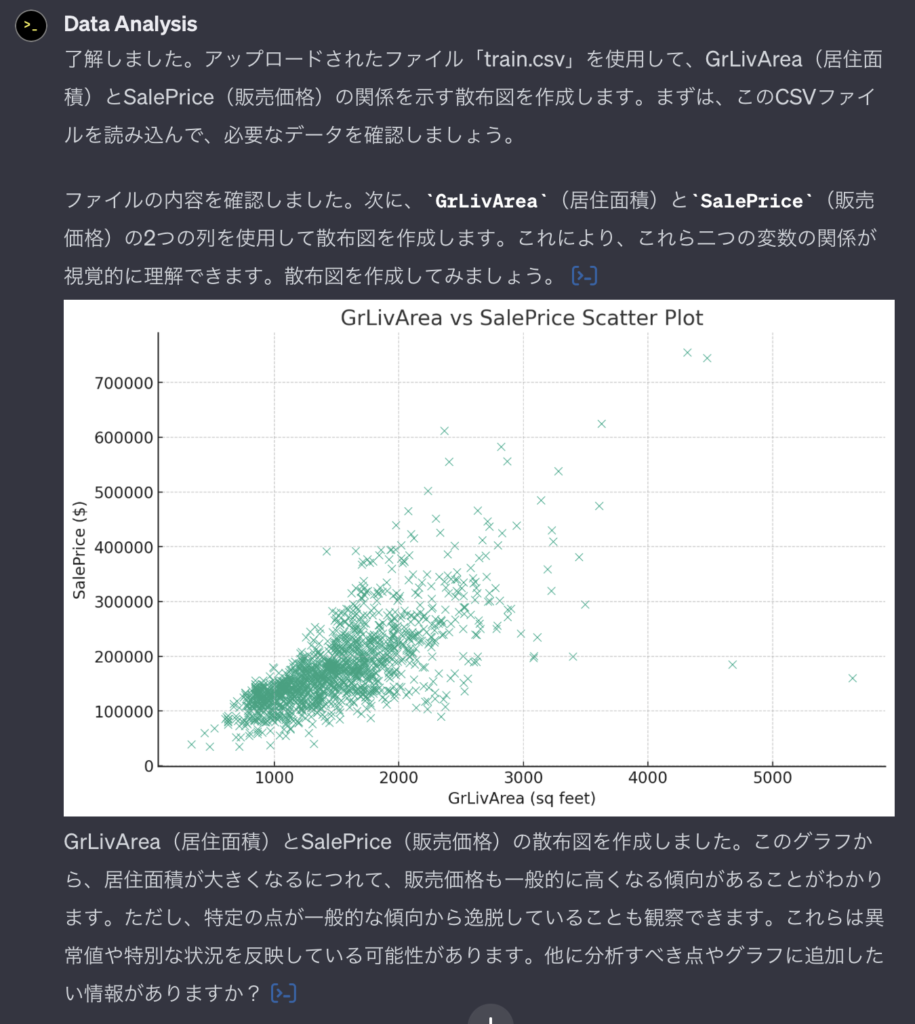
適切なプロンプトを支持することにより、異常値に関しても示唆してくれます。依頼者側の知識が試されますね。
モデリングに関しては、ランダムフォレストを用いています。確かにどのパターンにおいても非常に強力なモデリングですが、train_test_splitなどを用いて複数のRMSEを算出し比較をしてほしかったです。
5. 結果
与えられたデータをchatGPTに丸投げをしても、適切な解析を短時間で行なってくれるため、非常に強力なツールになります。ただし、精度を上げるためには、更に詳細な指示を出す必要があるため、依頼者側の理解や知識が重要になってきます。
感想
chatGPTの出現により、機械学習の勉強が意味がなくなるのではないかと少し心配なところがありましたが、chatGPTを使用する側の知識が重要な事が改めてわかりました。
chatGPTを使って時間短縮できるところは大いに活用しつつ、自身の知識もつけ、更に高精度なモデリングを短時間で行えることを目指します。
2023年も残り1日、来年も競プロに機械学習に精進して行きます。ここまで読んで頂きありがとうございます。


コメント