
みなさんこんにちは!こんぶちゃです。
今日は、YouTube Data API (この記事ではYouTube APIと記載) とPythonを使って、YouTube開発の世界への扉を開く方法についてお話ししましょう。初めてAPIに触れる方でも安心して学べるよう、基本的な概念から実際のコーディングまで丁寧に解説します。
今回のpythonの環境は、Google Colaboratory を用いています。
第1章: YouTube APIとは?
API(Application Programming Interface)は、ソフトウェアアプリケーション同士が情報をやり取りするための手段です。具体的には、プログラムが外部サービスやリソースと通信するための規約やツールを提供します。YouTube APIは、YouTubeプラットフォームで提供されているAPIであり、YouTubeの機能やデータにアクセスするための方法を開発者に提供します。
1.1 APIの基本原則
- エンドポイント(Endpoints): APIエンドポイントは、特定のリクエストを送信するためのURLです。YouTube APIのエンドポイントは、YouTubeの様々な機能にアクセスするためのゲートウェイとなります。
- HTTPメソッド: APIリクエストは通常、HTTPメソッド(GET、POST、PUT、DELETEなど)を使用して行われます。これによって、要求の性質や目的を指定します。
- 認証: 多くのAPIは、セキュリティのために認証手段を必要とします。YouTube APIも認証が必要であり、認証トークンを使ってリクエストを行います。
1.2 YouTube APIの用途
YouTube APIは多くの用途に使用できます:
- 動画の検索: YouTube APIを使用すると、特定のキーワードやクエリに基づいてYouTube上の動画を検索できます。
- 動画のアップロード: 自分のYouTubeチャンネルに動画をアップロードすることも、YouTube APIを使用することで実現できます。
- 動画情報の取得: 特定の動画の詳細情報や統計データ(再生回数、いいねの数など)を取得できます。
- コメント管理: APIを使用して、動画へのコメントを読み取ったり、返信をしたりすることができます。
1.3 なぜYouTube APIを使用するのか?
- カスタマイズされたアプリケーションの開発: YouTube APIを使用することで、独自のYouTube関連アプリケーションを開発できます。例えば、動画のカスタム検索エンジンや統計情報を提供するツールなどを作成できます。
- ユーザーエクスペリエンスの向上: YouTube APIを組み込むことで、ユーザーエクスペリエンスを向上させることができます。特定のカテゴリの動画を自動的に集めて表示するアプリや、YouTubeデータを分析してコンテンツ戦略を立てるツールなどが作成できます。
以上が、YouTube APIについての基本的な概念です。次章では、Pythonを使ってYouTube APIを操作する方法について学んでいきます。お楽しみに!
第2章: YouTube APIを使ってみよう!
この章では、Pythonを使用してYouTube APIを実際に操作する方法について学びます。YouTube APIを使って、動画の検索、動画情報の取得、コメントの管理など、基本的な操作を詳しく解説します。
3.1 YouTube APIの認証
まず最初に、YouTube APIを使用するためには認証が必要になります。APIキーの取得やOAuth認証の設定方法については下記のページを参考にしました。

ここで取得できたAPIキーを次で用います。
3.2 動画の検索
YouTube APIを使用して、特定のキーワードやクエリに基づいて動画を検索する方法を学びます。検索結果を取得し、それを解析して表示する方法を詳しく解説します。
まず、YouTube Data APIを使用するために必要なライブラリをインポートし、APIキーを使用してYouTube APIを初期化していきます。ここでのAPIキーは、先ほど取得したYouTube APIキーになります。このAPIキー(認証情報)を持つクライアントがYouTube APIにアクセスできます。
from apiclient.discovery import build
# YouTube Data APIのAPIキーを指定します(※ここに自分のAPIキーを入力してください)
YOUTUBE_API_KEY = "ここに自分のYoutube APIのAPIキーを入力して下さい"
# YouTube APIを初期化し、youtubeオブジェクトを作成します
# 'youtube'はAPIのサービス名、'v3'はAPIのバージョン、developerKeyにAPIキーを指定します
youtube = build('youtube', 'v3', developerKey=YOUTUBE_API_KEY)早速、検索をしていきます。ここでは、よくYouTubeで見ている’中田敦彦’をキーワードに検索をかけていきます (YouTube大学の楽しいです♪)
# 必要なパラメータを指定してYouTube APIのsearchリクエストを作成します
search_response = youtube.search().list(part='snippet', q='中田敦彦', type='video')
# searchリクエストを実行し、APIからのレスポンスを取得します
output = search_response.execute()
display(output)YouTube.search().list()の中身のパラメータは下記になります。
- ‘part’パラメータはAPIから取得するデータの種類を指定します。’snippet’は動画の基本情報を取得します。
- ‘q’パラメータは検索キーワードを指定します。この場合、’中田敦彦’というキーワードで検索を行います。
- ‘type’パラメータは検索結果の種類を指定します。’video’は動画を指定しています。
上記のコードを実行すると下記になります・・・。タイトルなどの情報が載っていますので、情報は取得できていそうですが、非常に見にくいです(JSON形式)。
{'kind': 'youtube#searchListResponse',
'etag': 'BeprJxVgOvzrLSQmmBASL9x32gM',
'nextPageToken': 'CAUQAA',
'regionCode': 'US',
'pageInfo': {'totalResults': 436983, 'resultsPerPage': 5},
'items': [{'kind': 'youtube#searchResult',
'etag': '9ElDezC1Vubp2jVKUWWVlbob5D8',
'id': {'kind': 'youtube#video', 'videoId': 'z25d6qL17fc'},
'snippet': {'publishedAt': '2023-10-13T10:01:00Z',
'channelId': 'UC6kSLiIgAcbXNSxf0JHjy5g',
'title': '【中国電気自動車BYDの衝撃】中田がシンガポールで見たクルマ業界の未来とは?',
'description': '【トヨタの危機・BYDの衝撃】の動画はこちら 前編: https://youtu.be/7meY4b9G4vI 後編: https://youtu.be/dChTUs8ent8 中田敦彦 ...',
'thumbnails': {'default': {'url': 'https://i.ytimg.com/vi/z25d6qL17fc/default.jpg',
'width': 120,
'height': 90},
'medium': {'url': 'https://i.ytimg.com/vi/z25d6qL17fc/mqdefault.jpg',
'width': 320,
'height': 180},
'high': {'url': 'https://i.ytimg.com/vi/z25d6qL17fc/hqdefault.jpg',
'width': 480,
'height': 360}},
'channelTitle': '中田敦彦のトーク - NAKATA ATSUHIKO TALKS',
'liveBroadcastContent': 'none',
'publishTime': '2023-10-13T10:01:00Z'}},
以下続く(別動画の基本情報)また、上記の内容では次のことがわからないです。
- 文字の羅列になっていて見づらい(JSON形式)
- 情報が5つしか載っていない
- 順番が最新日付順 (再生順にしたい)
- チャネルIDでは検索できない
そのため、取得動画の数を増やし、再生順にしつつ、表形式にしていきます。また、検索ワードかチャネルIDのどちらかで検索できるようにしていきます。
import pandas as pd
def get_video_details(q='', channel_Id='', part='id,snippet', order='date', maxResults=5, num=1):
"""
YouTube Data APIを使用して、指定したキーワード(q)またはチャンネルID(channel_Id)に関連する動画情報を取得します。
Parameters:
q (str): 検索キーワード(任意)。指定した場合、このキーワードに関連する動画を検索します。
channel_Id (str): チャンネルID(任意)。指定した場合、このチャンネルに関連する動画を検索します。
part (str): 取得するリソースの部分(任意)。デフォルトは'id,snippet'です。
order (str): 動画の並べ替え方法(任意)。デフォルトは'date'です。
maxResults (int): 1回のリクエストで取得する最大の結果数(任意)。デフォルトは5です。
num (int): 取得するページ数(任意)。デフォルトは1です。
Returns:
pd.DataFrame: 取得した動画情報をDataFrameとして返します。各行は1つの動画に対応します。
"""
if not q and not channel_Id:
print("キーワード(q)またはチャンネルID(channel_Id)を入力してください。")
return
dic_list = []
# channelIdパラメータを追加している箇所
search_response = youtube.search().list(part=part, q=q, channelId=channel_Id, order=order, maxResults=maxResults)
output = search_response.execute()
for i in range(num):
dic_list = dic_list + output['items']
# 次のページのデータを取得する
if 'nextPageToken' in output:
search_response = youtube.search().list(part=part, q=q, channelId=channel_Id, order=order, maxResults=maxResults, pageToken=output['nextPageToken'])
output = search_response.execute()
else:
break
items = dic_list
# 必要な情報を取得し、データフレームに変換します
ddf = pd.DataFrame({
'videoId': [item['id']['videoId'] for item in items],
'publishedAt': [item['snippet']['publishedAt'] for item in items],
'channelId': [item['snippet']['channelId'] for item in items],
'title': [item['snippet']['title'] for item in items],
'description': [item['snippet']['description'] for item in items],
'channelTitle': [item['snippet']['channelTitle'] for item in items],
'thumbnails': [item['snippet']['thumbnails']['default']['url'] for item in items]
})
# publishedAt列を日時型に変換
ddf['publishedAt'] = pd.to_datetime(ddf['publishedAt'])
return ddf
# 指定した値でqとchannel_Idを固定
q = '中田敦彦'
channel_Id = ''
# チャネルIdが空白の場合は、検索ワードで検索。
# 例えば、中田敦彦のチャネルID 'UCFo4kqllbcQ4nV83WCyraiw' で検索すれば、中田敦彦のYouTube大学の動画だけで検索できます
# パラメータを指定して動画情報を取得します(orderはデフォルトで'date'、maxResultsはデフォルトで5、numはデフォルトで1)
df = get_video_details(q=q, channel_Id=channel_Id, part='id,snippet', order='viewCount', maxResults=50, num=2)
# 取得した動画情報をデータフレームとして表示します
dfこちらでは、get_video_searchのdefを定義してデータを取得しています。ポイントになる箇所は
youtube.search().list()にorderとmaxResultsを設定- order : 出力の順番を定義できます。標準では日付の新しい順ですが、ここでは再生回数順 (viewCount) にしています。
- maxResults: 取得する数を指定できます。最大50件です。
- channelId: チャネルIDを設定できます。チャネルIDの取得方法は、YouTube APIでワード検索(q)をして目的のチャネルを見つけたら、その情報をコピーするのがAPIを使える人には手っ取り早いです。
for i in range(num): 50件以上の情報を取得する場合に次ページ情報を取得youtube.search().list_next()指定したリクエストと出力結果を入力することにより、次ページ情報を取得できます。
ddf = pd.DataFrame(): 各項目の情報を取得して、pandasの表形式にしています。- itemsに1つのビデオ情報の塊が複数個あり、それを内包表記でひとつづつ取り出す
- JSONデータは辞書型のデータ構造のため、項目を指定して欲しい情報を入手
- それぞれの項目の取得方法は下記の表を参照にして下さい
| 項目名 | 取得方法 | 説明 |
|---|---|---|
| videoId | item['id']['videoId'] | 各動画のIDを取得します。 |
| publishedAt | item['snippet']['publishedAt'] | 動画の公開日時を取得します。 |
| channelId | item['snippet']['channelId'] | 動画を投稿したYouTubeチャンネルのIDを取得します。 |
| title | item['snippet']['title'] | 動画のタイトルを取得します。 |
| description | item['snippet']['description'] | 動画の説明文を取得します。 |
| channelTitle | item['snippet']['channelTitle'] | 動画を投稿したYouTubeチャンネルのタイトルを取得します。 |
| thumbnails | item['snippet']['thumbnails']['default']['url'] | 動画のサムネイル画像のURLを取得します。 |
出力結果 *上位6件のみ表示しています。

タイトルなどを取得できたが、再生回数、いいねの数、コメントの数などが表示されていません。それぞれのビデオIDをyoutube.videos().list()に渡すことにより取得が可能になります。また、再生時間も一緒に取得していきます。
*上記で取得したデータフレームdfを用いています。
import re
# YouTube Data APIを使用して動画の具体的な再生回数やいいね数を取得する関数を作成
def get_statistics(id):
video_response = youtube.videos().list(part='statistics,contentDetails', id=id).execute()
statistics = video_response['items'][0]['statistics']
statistics['duration'] = video_response['items'][0]['contentDetails']['duration']
return statistics
# ISO 8601形式の時間を秒に変換する関数を定義
def iso8601_to_seconds(iso_duration):
# 正規表現を使用して、P、T、H、M、Sを取り除く
iso_duration = re.sub(r'P|T|H|M|S', '', iso_duration)
# 時間、分、秒に分解して秒に変換
parts = iso_duration.split('S')
seconds = 0
if len(parts) > 0:
seconds += int(parts[-1])
if len(parts) > 1:
seconds += int(parts[-2]) * 60
if len(parts) > 2:
seconds += int(parts[-3]) * 3600
return seconds
# DataFrameにvideoIdを入力して、YouTube Data APIを使用して動画の詳細情報を取得
df_static = pd.DataFrame(list(df['videoId'].apply(lambda x: get_statistics(x))))
# DataFrameを結合し、必要な列を整形
df_output = pd.concat([df, df_static], axis=1)
cols = ['viewCount', 'likeCount', 'favoriteCount', 'commentCount']
df_output[cols] = df_output[cols].fillna(0).astype(int)
# ISO 8601形式の動画の長さを秒に変換
df_output['duration'] = df_output['duration'].apply(lambda x: iso8601_to_seconds(x))
# 取得した動画情報を表示
df_output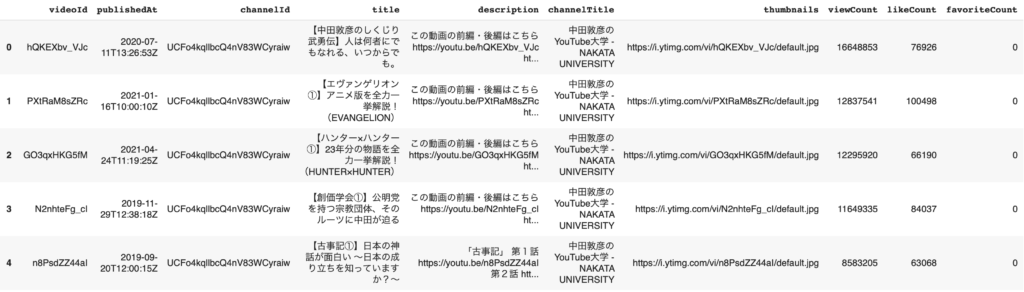
再生回数、いいねの数などを取得できました。上記では隠れてしまっていますが、再生時間(duration)も秒に変換して取得できています。
次に特定のvideoIDのコメントを拾ってみます。
3.3 コメント情報の取得
特定の動画へのコメント情報の取得方法を学びます。コメントの情報を入手するコード例を解説します。
import pandas as pd
def get_all_comments(videoId):
dic_list = []
nextPageToken = None
while True:
search_response = youtube.commentThreads().list(
part="snippet,replies",
videoId=videoId,
maxResults=100, # 1回のリクエストで取得できる最大コメント数
pageToken=nextPageToken
)
output = search_response.execute()
dic_list += output['items']
# 次のページが存在する場合はそのページのコメントも取得
nextPageToken = output.get('nextPageToken')
# 次のページがない場合はループを終了
if nextPageToken is None:
break
items = dic_list
# 必要な情報を取得し、データフレームに変換します
ddf = pd.DataFrame({
'authorDisplayName': [item['snippet']['topLevelComment']['snippet']['authorDisplayName'] for item in items],
'authorChannelId': [item['snippet']['topLevelComment']['snippet']['authorChannelId']['value'] for item in items],
'authorProfileImageUrl': [item['snippet']['topLevelComment']['snippet']['authorProfileImageUrl'] for item in items],
'textDisplay': [item['snippet']['topLevelComment']['snippet']['textDisplay'] for item in items],
'publishedAt': [item['snippet']['topLevelComment']['snippet']['publishedAt'] for item in items],
'videoId': [item['snippet']['topLevelComment']['snippet']['videoId'] for item in items]
})
# publishedAt列を日時型に変換
ddf['publishedAt'] = pd.to_datetime(ddf['publishedAt'])
return ddf
# 指定したvideoIdの動画に対するすべてのコメントを取得
df = get_all_comments(videoId="*****") # ***にvideoIdを入力して下さい。動画検索でvideoIDも取得できます。
df
* ここにコメントが表形式で出力されます。個人のアカウントのため内容は割愛しています。
次に、チャンネルIDの情報も取得していきます。
3.4 チャネル情報の取得
特定のチャンネル情報の取得方法を学びます。チャネルIDの情報を入手するコード例を解説します。
# YouTubeチャンネルの情報を取得する関数
def get_channel_info(channel_id):
# YouTube Data APIを使用してチャンネルの基本情報と統計情報を取得するリクエストを作成
request = youtube.channels().list(
part='snippet,statistics',
id=channel_id
)
# リクエストを実行し、レスポンスを取得
response = request.execute()
# レスポンスから必要な情報を取得してDataFrameに変換
df1 = pd.DataFrame({
'channelId': response['items'][0]['id'], # チャンネルID
'title': response['items'][0]['snippet']['title'], # チャンネルのタイトル
'publishedAt': response['items'][0]['snippet']['publishedAt'] # チャンネルの公開日時
})
df2 = pd.DataFrame([response['items'][0]['statistics']]) # 統計情報(登録者数など)
# DataFrameを結合し、publishedAt列を日時型に変換
ddf = pd.concat([df1, df2], axis=1)
ddf['publishedAt'] = pd.to_datetime(ddf['publishedAt'])
return ddf
# 指定したチャンネルIDに関する情報を取得し、DataFrameとして表示
df = get_channel_info(channel_id="UCFo4kqllbcQ4nV83WCyraiw")
df
この章では、YouTube APIの基本的な操作方法を学び、Pythonを使用してそれらを実際に実行する方法を学びました。次章では、これらの知識を応用して実践的なプロジェクトを行います。準備ができたら、次に進んでみましょう!
第3章: 実践プロジェクト
最後に、学んだ知識を活かして簡単なデータ分析を行いましょう。YouTube APIから動画情報を取得してグラフ化を行うことで、実際のプロジェクトに応用できるスキルを身につけます。
3.1 いいねの数と再生回数
いいねの数が多ければ、再生回数も増えていくと想定されるため、散布図で傾向性を確認していきます。
今回も中田敦彦のYouTube大学のチャンネルIDを用いていきます。データは、500件を取得しました。
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib # インポートできていなければ !pip install japanize-matplotlib で入れる必要あります
%matplotlib inline
# seabornを使用して散布図を描画
sns.scatterplot(data=df_output, x='likeCount', y='viewCount')
# x軸とy軸にラベルを付けたり、日本語表示を可能にするためにjapanize_matplotlibを使用
plt.xlabel('いいねの数')
plt.ylabel('再生回数')
plt.title('再生回数といいねの数の関係')
plt.show()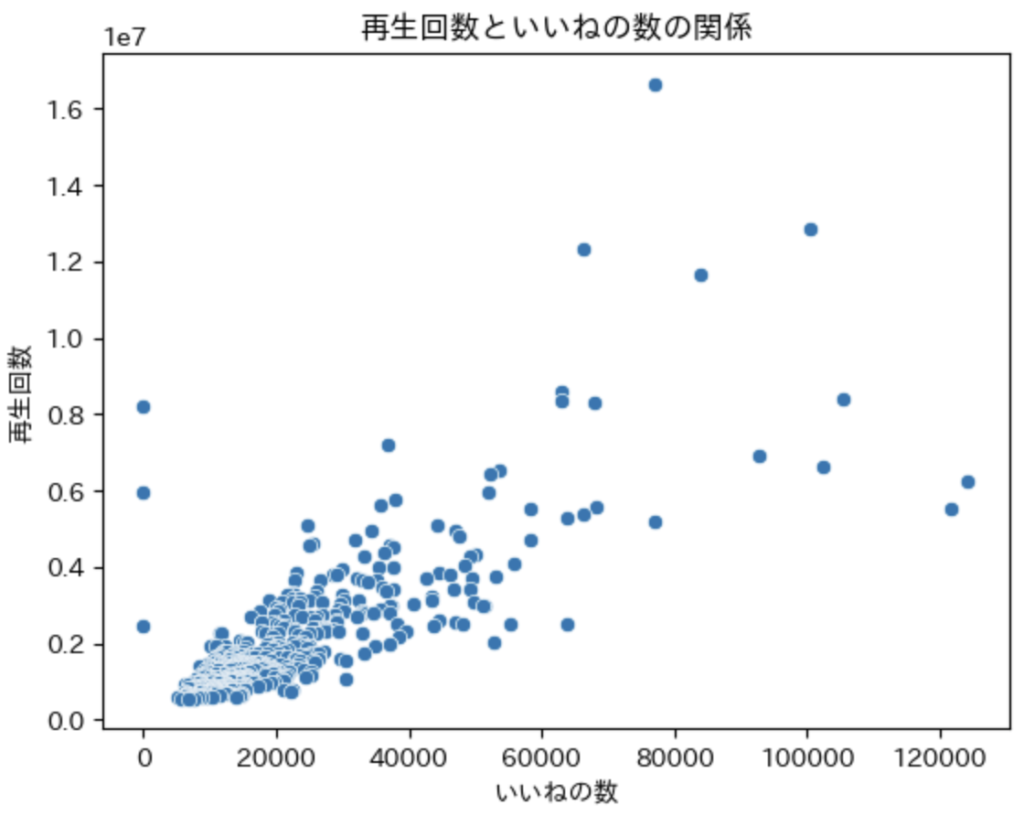
いいねの数が増えれば、再生回数も増えていることがわかります。ただし、左側の3点部分にいいねの数が 0 になっているところがあります。この部分のデータをピックアップして確認してみたところ評価(いいねと嫌いの数)が非開示になっていました。つまり、原因がわかる異常値として扱うことができます。
3.2 再生時間と再生回数
次に再生時間と再生回数には相関があるかを確認していきます。
# durationが最大の行を抽出
max_duration_row = df_output.loc[df_output['duration'].idxmax()]
# プロットを作成
plt.figure(figsize=(12, 5))
sns.scatterplot(data=df_output, x='duration', y='viewCount')
# 最大のdurationの点に赤い矢印を追加
plt.annotate('',
xy=(max_duration_row['duration'], max_duration_row['viewCount']),
xytext=(max_duration_row['duration']-5000, max_duration_row['viewCount']+5000),
arrowprops=dict(facecolor='red', shrink=0.05))
# x軸とy軸にラベルを付ける
plt.xlabel('再生時間')
plt.ylabel('再生回数')
# タイトルを付ける
plt.title('再生回数と再生時間の関係')
# グラフを表示
plt.show()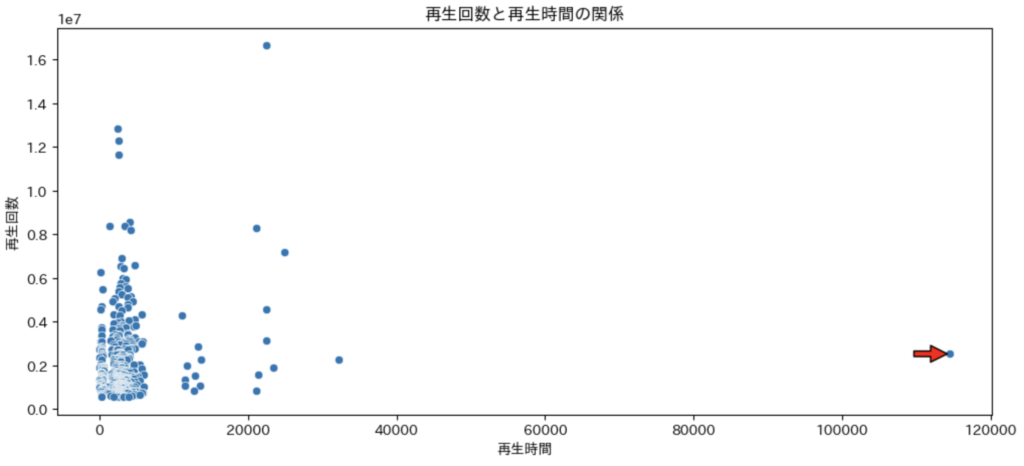
上記のグラフから再生時間と再生回数は相関が見られない。また、一つだけ飛び抜けた再生時間のビデオがあります(赤矢印つけています)。年末の500万人突破Liveでした。
3.3 公開日時と再生回数
次に公開日時と再生回数には相関があるかを確認していきます。
# プロットのサイズを指定
plt.figure(figsize=(16, 5))
# seabornを使用して折れ線グラフを描画(x軸にはpublishedAt、y軸にはviewCountを指定)
sns.lineplot(data=df_output, x='publishedAt', y='viewCount', marker='o')
# x軸とy軸にラベルを付ける
plt.xlabel('公開日時')
plt.ylabel('再生回数')
# タイトルを付ける
plt.title('公開日時と再生回数の関係')
# グラフを表示
plt.show()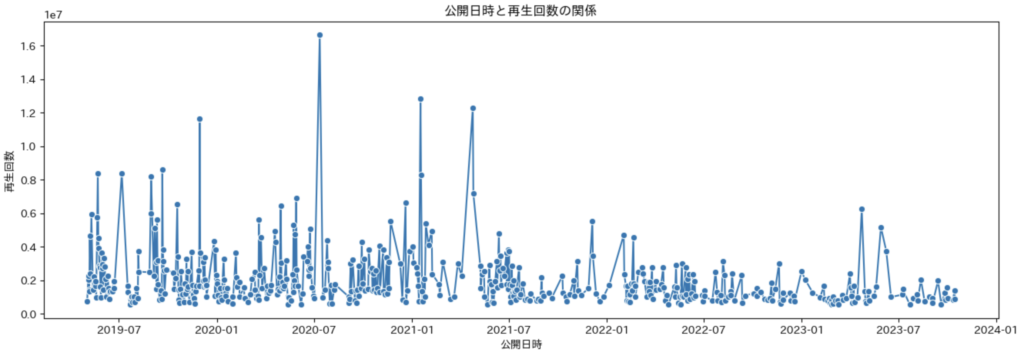
最近も楽しい動画がたくさんありましたが、2019年から2021年の方が再生回数が多い動画が多いことがわかります。コロナでの外出規制でYouTubeをみたり、普遍的な動画が多いため、今でも過去の動画を楽しめることが影響しているのではないかと思います(私の考えです)。
3.4 コメントの数と再生回数
次にコメントの数と再生回数に相関があるかを確認していきます。
# seabornを使用して散布図を描画
sns.scatterplot(data=df_output, x='commentCount', y='viewCount')
# x軸とy軸にラベルを付ける
plt.xlabel('コメント数')
plt.ylabel('再生回数')
# タイトルを付ける
plt.title('再生回数とコメント数の関係')
# グラフを表示
plt.show()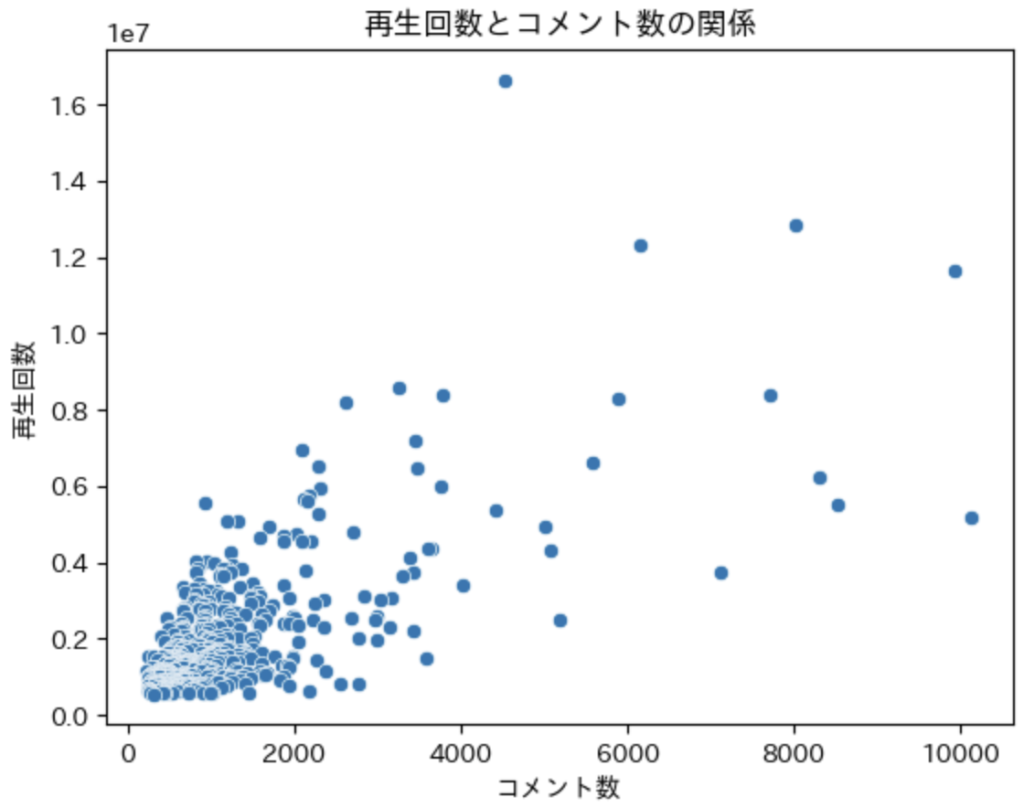
いいねの数と同様、コメント数が増えれば、再生回数が増えることがわかります。
今回の解析はここまでです。タイトルの頻出単語などを用いたら、どのような単語を入れるべきかなどの解析ができそうなのですが、現状の私の知識では力が及びませんでした。今後の課題としたいと思います。
第4章: 参考
今回の投稿にあたって、下記のページを参考にさせていただいています。
感想
今回は、YouTubeのAPIを扱ってみました。APIが何かもわかっていなかったのですが、この機会に調べて、更にAPIでデータも引き出すことができました。APIを使うと様々な情報にアクセスできそうですので、今後も活用していきたいです。
データ解析の学習としてGoogle Career Certificatesに参加しました。問いかけや倫理なども含んだコースで非常にためになります。来月はこちらに注力しつつ、余力があったらKaggleも挑戦していきたいと思います。
認定書がもらえたら、こちらで連絡していきます(自分へのプレッシャー笑)
目指せ、データアナリスト(*^▽^)/


コメント