
こんにちは、こんぶちゃです!
初心者視点からKaggleのTitanicを解いて解説をしていきます。
- データサイエンスに興味がある方
- Kaggleを見よう見まねで解いてみたが、内容がピンとこない方
- エクセルで扱えない大量のデータの扱いに困っている方
まだまだ学習の身ですので、分析としては不足している部分も多々あるかと思いますが、その部分は同じ学習者として温かい気持ちで応援&ご助言頂けば嬉しいです。
では早速行ってみましょう!
今回の問題:Titanic – Machine Learning from Disaster
Titanic – Machine Learning from Disaster
データ解析の流れ (ワークフロー)
データ解析を進める際にデータを前にして、どのように進めていいのかわからなくなることがあると思います (私がそうでした)。
沢山のデータがあるので、手当たり次第にデータを整え、可視化して、、、。ふと、自分は今何のためにやっているのだろうっと途中で思ったりしていました。
そのため、一連の流れを意識しながらデータ解析を行うことが非常に重要になってきます。
データ解析のワークフローとポイント
| ステップ | 説明 | 重要なポイント |
|---|---|---|
| 1. 問題の定義と目標の設定 | 解決したい問題を定義し、ビジネス上の目標を設定します。 | 解析の成果がビジネスにどのように活かされるかを明確にする。 |
| 2. データの収集 | 必要なデータソースからデータを収集します。 | データの品質や信頼性を確認する。 |
| 3. データの整形と前処理 | データを欠損値や異常値を処理し、解析に適した形式に整形します。また、データの探索的分析も行います。 | データの品質向上が分析の結果に大きな影響を与える。データの特徴や相関関係を把握し、洞察を得る基盤を築く。 |
| 4. データモデリング | データをモデルに適用し、予測や分類などの解析を行います。 | モデルの選択とパラメータの調整がモデルの性能に影響する。 |
| 5. モデルの評価と改良 | モデルの予測精度を評価し、必要に応じて改良を行います。 | 解析結果の信頼性向上のために継続的な改善が重要。 |
| 6. 結果の可視化と報告 | 解析結果を可視化し、報告書やプレゼンテーションとしてまとめます。 | 結果をわかりやすく伝えることが重要。 |
| 7. 応用と展望 | 解析結果を活用し、応用や展望を考えます。 | ビジネスへの応用や今後の研究計画につなげる。 |
Titanicのケースで順番に見ていきたいと思います。
1. 問題の定義と目標の設定
まずは、今回解決したい問題を明確化です。Kaggleでは、明確な目的をすでに与えられています(参照:Description)。端的に言うと、
問題:Titanicでは、test.csvのIDの人が生き残ったかどうかを判断する
ただし、もう少し読み解くと下記の情報も記載されています。
- 1912年4月15日、処女航海中だった広く「沈まぬ船」と考えられていたタイタニック号が氷山と衝突した後、沈没しました。
- 残念ながら、乗船者および乗員合わせて2224人中1502人が生き残るための救命ボートが不足しており、命を落としました。
- 生き残ることには運も一部関与していましたが、一部のグループの人々は他よりも生き残る可能性が高かったようです。
(翻訳はchatGPT 3.5 を使用)
基本情報は、データ整形時にデータの認識の早さや、筋の良い仮説を立てる際にこのような情報が重宝します。
Kaggleでは問題が明確化でデータも整っていますが、実際の場合は問題をよく理解してどのようなデータ収集が必要かを基本情報と問題から判断する必要があります。
また、Kaggleにおいては提出するフォーマットも確認しておく必要があります。2列で下記に従う必要があります(折角解析しても提出フォーマットが違ったら0点になっちゃいますので)
- PassengerId (任意の順番でソート可能)
- Survived (生存者は 1、死亡者は 0)
2. データ収集
実務の場合は問題に対する必要なデータを集めるところから始まります。一部不足データは、関係者(他部署やメーカーなど)に問い合わせをしてデータを入手する必要があります。
Kaggleの場合はデータが与えられいます。早速データを読み込んでもいいのですが、事前にデータの構成要素などHP上で示してくれていますので、それをまずは確認するのがいいと思います。
確認ポイント ( “Data” タブで確認できます )
- 与えられるファイル:training.csv, test.csv
- データ辞書 (Data Dictionary):変数名、意味、取りうる値
- (可能であれば) データ概略
gender_submission.csvファイルも与えられますが、これは提出の参考ファイル。pythonで読み込んだときになんだこれ?っとならないようにデータ構成を見ておいた方が良いです (なんだこれっとなりました・・・)
特にデータディクショナリーに関しては、それぞれが何の項目を指しているかを示しているため、しっかり見ておいた方がいいです
データ概略に関しては、プログラムで確認するためここでは必須ではないが、プログラムに慣れていない場合は、ここで大枠を確認しておいた方が理解が早いと思います。
# 各モデルのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# データの読み込み
df_train = pd.read_csv("/kaggle/input/titanic/train.csv")
df_test = pd.read_csv("/kaggle/input/titanic/test.csv")
# データの確認(shpeを使ってそれぞれのデータサイズを確認
print(f'df_train: {df_train.shape}')
print(f'df_test: {df_test.shape}')
# データの中身を確認
df_train.head()3. データの整形と前処理
収集したデータがそのまま使えるデータになっていることは稀であるため、データ解析をするための整形と前処理が必要になる。
- データの確認と理解
- データの確認
- データの理解
- 不要なデータの削除
- 欠損値の処理
- 外れ値の処理
- 特徴量の前処理
- 特徴量エンジニアリング
- カテゴリカルデータの処理
- データの正規化または標準化
- データの分割
3-1. データの確認と理解
3-1-1. データの確認
info()を用いることにより欠損値とデータ型を確認することができる
- Calum: カラム名。df_testには Survived がないことがわかる。他のカラムは同じ
- Non-Null Count: データがある項目の数。
- 下記のような思いを巡らすことができる
- Cabinは空白が多いので、あまり使えなそう
- Ageは、いくつか空白があるので、補完が必要そう
- 下記のような思いを巡らすことができる
# 1. データ内容の確認
df_train.info()
print('_'*40) #区切り用です
df_test.info()
# 以下が出力内容
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
________________________________________
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
'''describe()を用いることにより基本統計量を確認できる。確認できる項目は以下
| 統計情報 | 説明 |
|---|---|
| count | 非欠損値(NaNではない値)の数を示します。 |
| mean | 平均値を示します。 |
| std | 標準偏差を示します。 |
| min | 最小値を示します。 |
| 25% | データの25パーセンタイル(第1四分位数)を示します。 |
| 50% | データの50パーセンタイル(中央値)を示します。 |
| 75% | データの75パーセンタイル(第3四分位数)を示します。 |
| max | 最大値を示します。 |
# 基本統計量の出力
df_train.describe()
# 出力結果は下記。見やすさのため .round(1) を上記に追加している。桁数丸め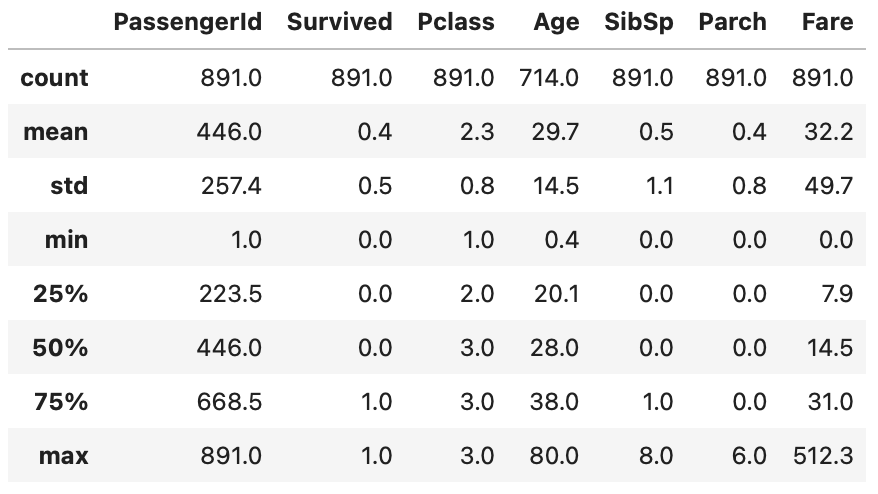
上記から下記のことを読み取れる
- 年齢 (Age) は大半が20 ~ 38 才の間 (25% ~ 50%)。最高年齢は80歳
- 運賃 (Fare) は大半が7.9 ~ 31 の間だが、一部高額な512も含まれる
describeにおいては、引数にinclude=[‘O’]を使うことによりobject型の統計情報を確認することができる
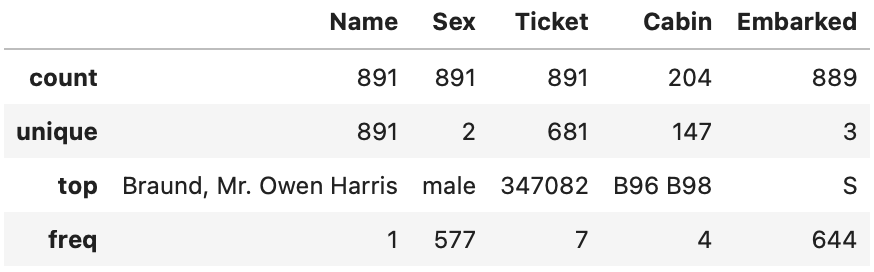
上記のobject型の基本統計量からは下記のことがわかる
- 名前 (Name) は、全員個別の名前がついている
- 性別 (Sex) は、2変数のみ(male, female)。meleが65% (577/891)
- Ticketはユニークなはずだが、約23%はユニークな番号になっていない
- Cabinの数(非欠損値)が少ない
- Embarkedには2つだけ欠損値が存在する
補足) 概略データのヒストグラム
hist()を使うことにより、データセットの数字型部分を簡易的なヒストグラムで表現することもできる
# データセットのヒストグラムの表示
df_train.hist()
plt.tight_layout() # タイトルとx軸が重なってしまうためグラフ間を広げる
plt.show()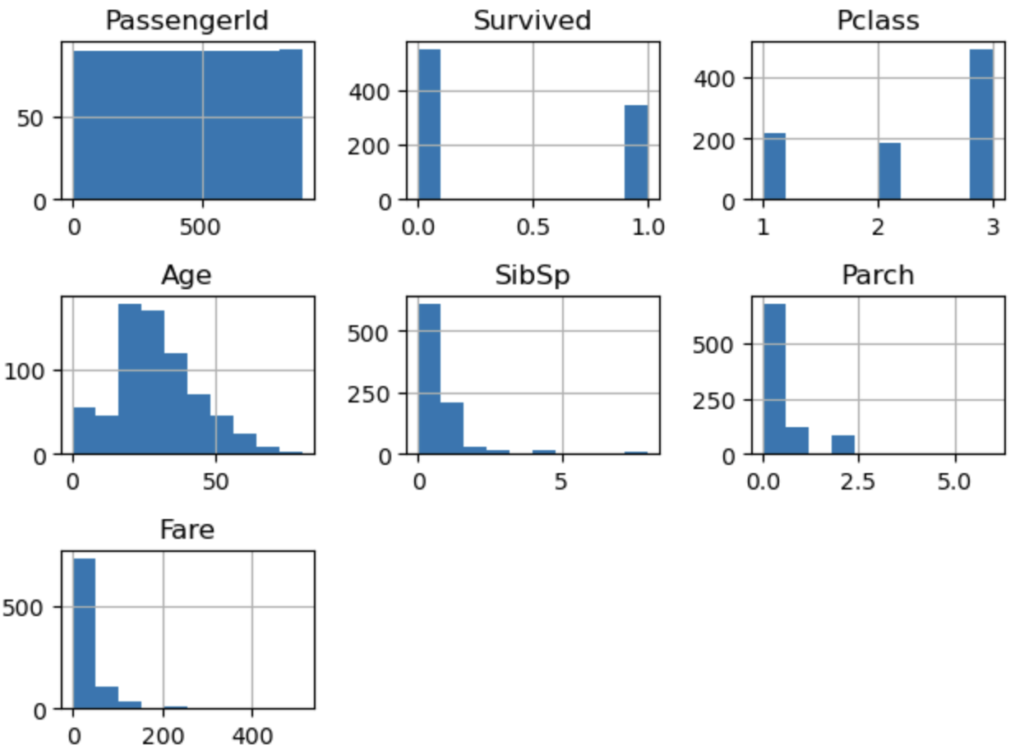
describeで表示を行った内容と同じだが、視覚化することにより理解が深まる
3-1-2. データの理解
データを観察し、仮定を立て、データを解析する。
仮説① Pclassが高い人は重要人物の可能性が高く生存率が高いのではないか?
結果① Pclassが高い人の方が生存率が高い
棒グラフを用いることにより視覚的に差異がわかりやすい。
*棒グラフの黒線は標準偏差を示す(標準設定)。黒線が長いとばらつきが大きいことを示す
# seabornの棒グラフを作成。paletteは色味の調整のため無くてもよい
sns.barplot(data=df_train, x='Pclass', y='Survived', palette='deep')
plt.show()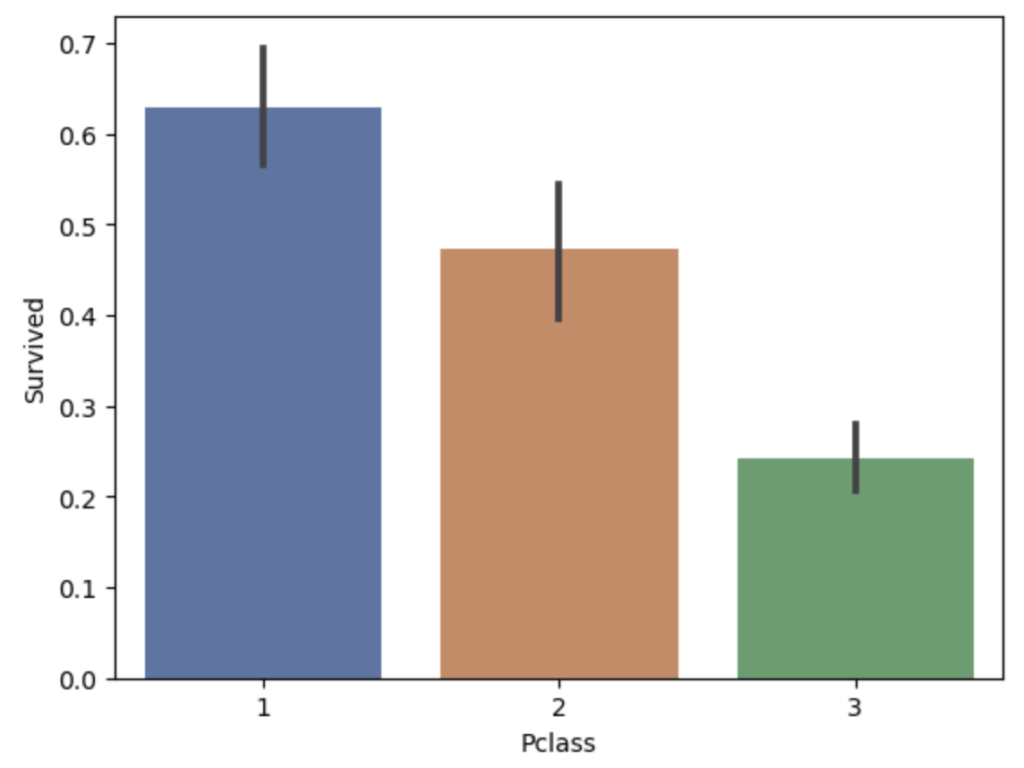
仮説② 家族(伴侶, 兄弟, 子供)がいた方が諦めずに生きるのでは?
結果② 独り身よりも家族がいる方が生き残る可能性が高い
上記同様に棒グラフで表しているが、subplotsを用いることにより2つのグラフを一体化している (y軸は同じくしている sharey=True )
# subplotsを用いることにより、行 1 x 列 2 のグラフを作成。
# barplotの中にax[?]とすることで、グラフの位置をしている
fig, ax = plt.subplots(1,2, figsize=(12,6), sharey=True)
sns.barplot(data=df_train, x='SibSp', y='Survived', palette='deep', ax=ax[0])
sns.barplot(data=df_train, x='Parch', y='Survived', palette='deep', ax=ax[1])
plt.show()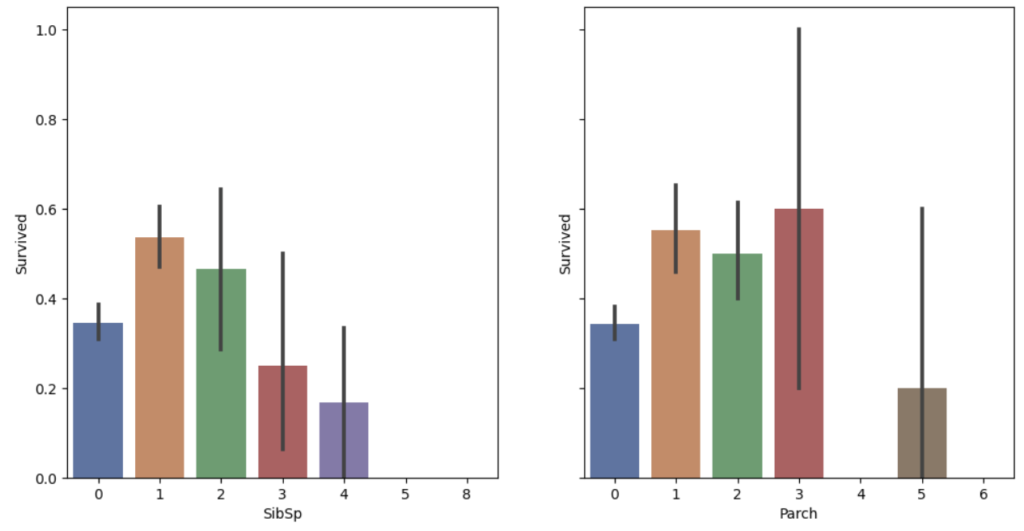
仮説③ レディファースト文化の国(イギリス)なので、女性が優先的に救命ボートに乗せてもらえたのではないか?
結果③ 明らかに女性の生存確率が高い(イギリス紳士カッコいい)
# x軸をSexとして棒グラフを作成
sns.barplot(data=df_train, y='Survived', x='Sex', palette='deep')
plt.show()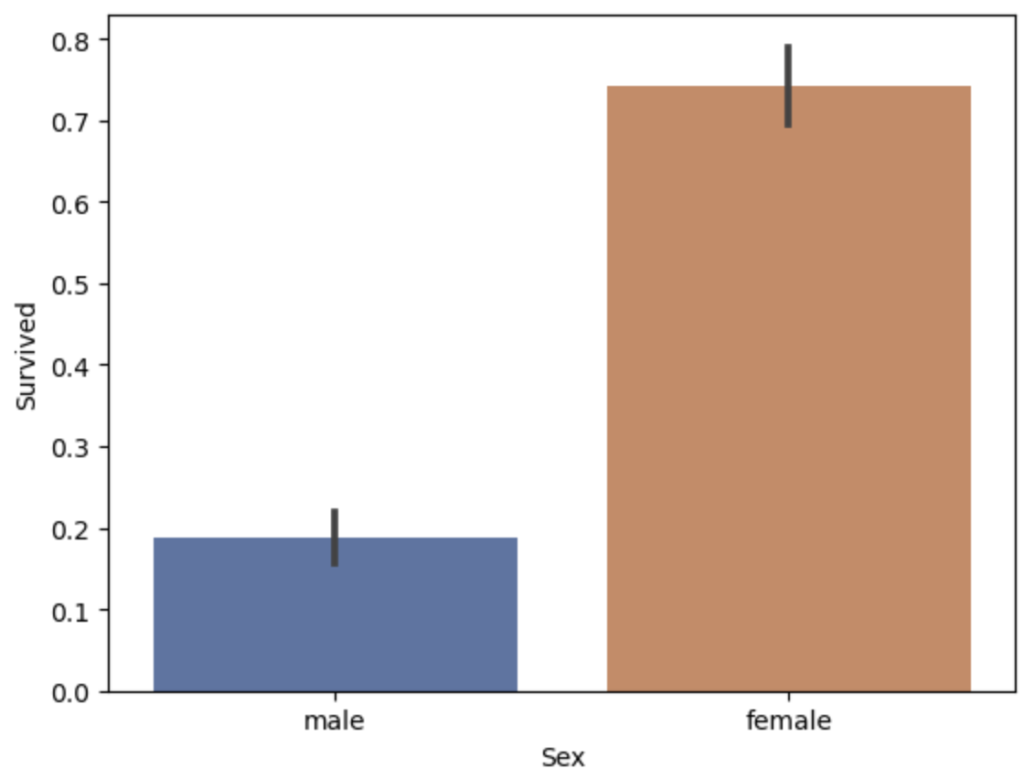
仮説④ 乗船港で生存率が変わるのではないか?
結果④ C = Cherbourg から乗船した人達の生存率が高い
# x軸をEmbarkedとして棒グラフを作成
sns.barplot(data=df_train, x='Embarked', y='Survived', palette='deep')
plt.show()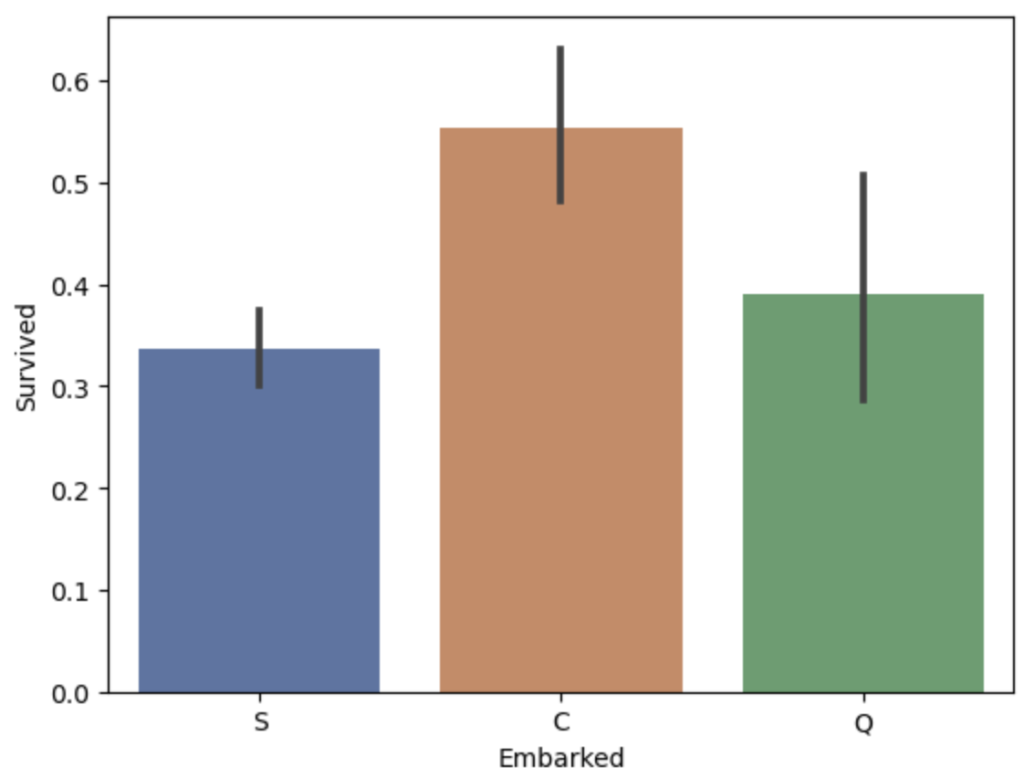
仮説⑤ 性別・Pclass・乗船港の組み合わせで明確な特徴が現れるか?
結果⑤ Pclassが高く、性別が女性だと生存確率が高い。乗船値:Q の男性だと生き残る可能性が低い
# 要素毎にグラフを作成するために、FacetGridを用いる。
# g.map内に左の順番に適用した、order, hue_orderを設定する (グラフの入れ替えを防ぐ)
g = sns.FacetGrid(data=df_train, col='Embarked')
g.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', order=[1,2,3], hue_order=['male', 'female'] ,palette='deep')
g.add_legend()
plt.show()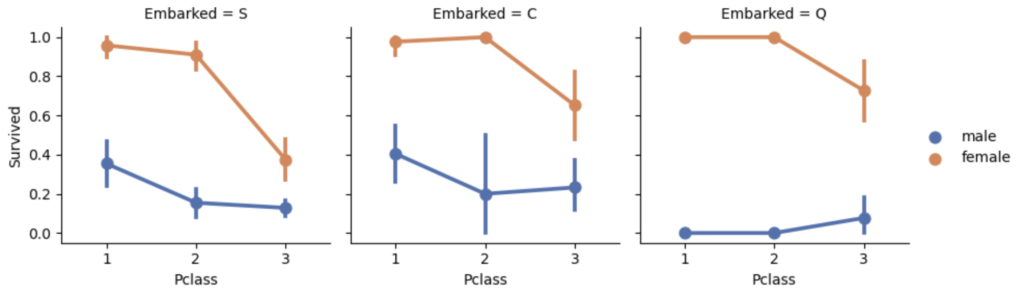
上記では、割合で見ているため、実際の数字が把握できてなくなってしまいます。特に実務においては、一つの事例が当てはまっただけで、傾向性があると間違う恐れがあると思います。そのため、実際の件数の確認も一緒に行った方が安全だと思います。
# ピポットテーブルを用いてそれぞれの人数を求める
df_train.pivot_table(columns=['Embarked','Pclass','Sex'], index=['Survived'], values='PassengerId', aggfunc='count')項目をグラフと揃えるためにカラムに [乗船港, クラス, 性別]、インデックスに [生死]として、乗客IDの数をカウントしている

乗船港 Q のクラス 1, 2 においては、非常に数が少なく判断されていることがわかる
仮説⑥ 年齢により生存率が高い年齢帯や低い年齢帯があるのではないか?
結果⑥ 18歳以下の生存率が少し高い。
年齢毎の傾向性は18歳以下, 18 ~ 35, それ以上で傾向性が変わる
# 生死で層別したスタック型のヒストグラムを作成する
sns.histplot(data=df_train, x='Age', hue='Survived', multiple='stack', binwidth=3)
plt.show()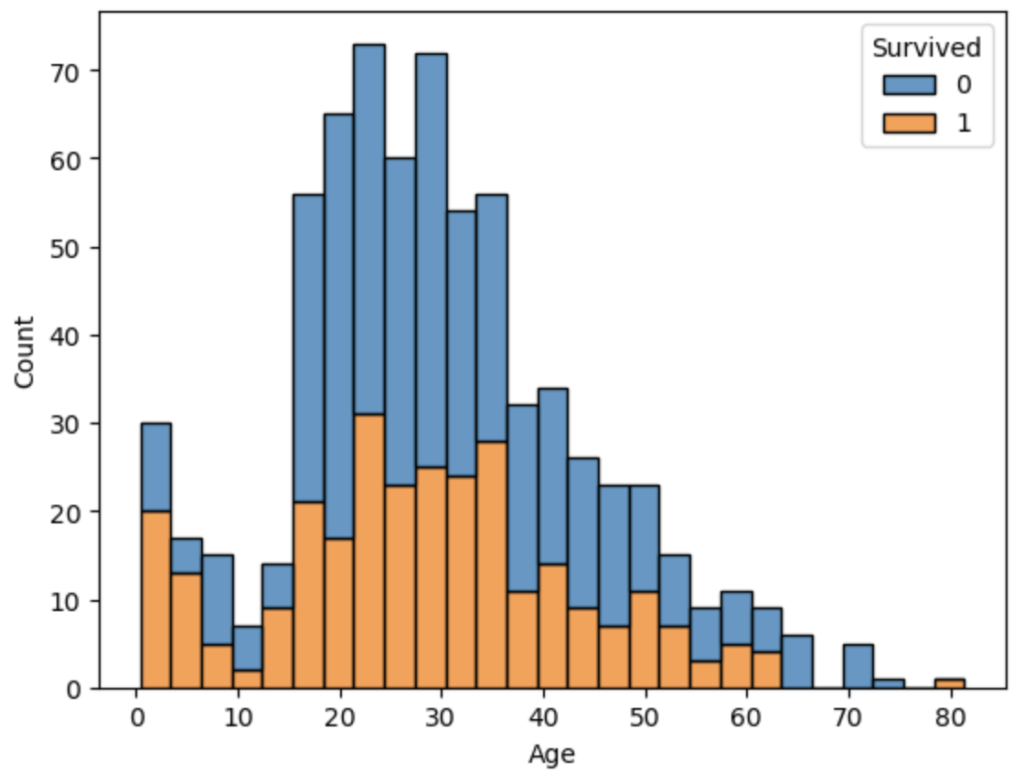
仮説⑦ 運賃(Fare)が高い方が重要人物が含まれ生存率が高いのではないか?
結果⑦ 運賃が高い方が生存率が高い。ただし、大半は低料金の人達である
# subplotsを用いて、二つのグラフを表示。
# 左側ax[0]に通常のヒストグラム。右側ax[1]に各項目における生死の割合を示した分布(multiple='fill')
fig, ax = plt.subplots(1,2,figsize=(12,5))
sns.histplot(data=df_train, x='Fare', bins=40, ax=ax[0])
sns.histplot(data=df_train, x='Fare', hue='Survived',bins=40, multiple= "fill", palette='deep', ax=ax[1])
plt.show()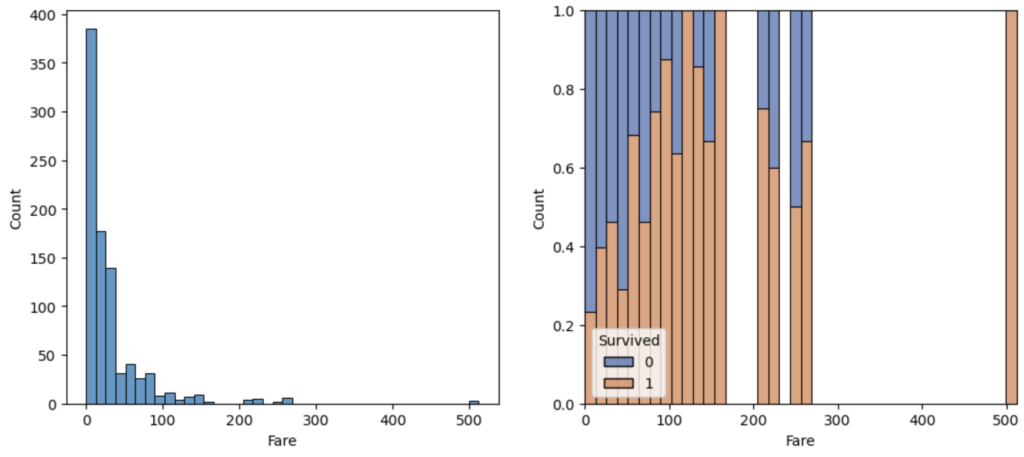
3-2. 不要なデータの削除
データの確認と理解により、今回の分析に用いないデータを削除する
- 名前 (Name): 全員別々の名前で規則性を見つけることができない
(タイトルで規則性をみつけている方もいらっしゃいました) - Ticket: 約2割ほど重複があり、データの信頼性が低い
- Cabin: 約2割ほどしかデータがなく、活用できない
データから上記の列を削除していく。ただし、データフレームは、df_train, df_test の2つがあるため、それぞれのデータフレームから削除する必要がある
# リストにトレーニングデータとテストデータを格納
datasets = [df_train, df_test]
cols = ['Cabin', 'Name', 'Ticket']
# 各データセットに対して列の削除を行い、元のデータセットを更新する
for df in datasets:
#inplace=True を用いる事により、元のデータセットを変えている
df.drop(cols, axis=1, inplace=True)
# 更新されたデータセットを表示(トレーニングデータ)
display(df_train.head(3))
# 更新されたデータセットを表示(テストデータ)
display(df_test.head(3))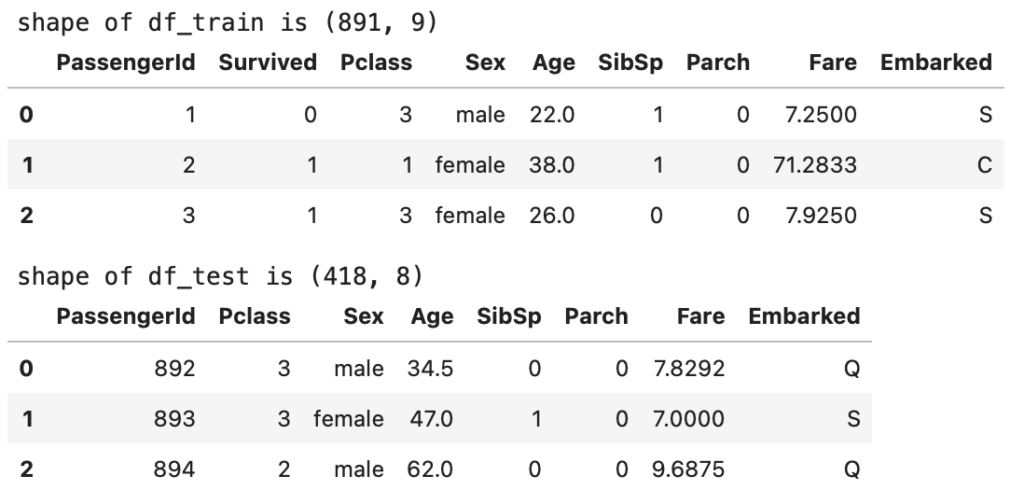
3-3. 欠損値の処理
データ確認を行った際にいくつかの欠損値があったため、この欠損値 (データにおいて欠けている値) の処理が必要になる。欠損値の処理の仕方としては主に下記の二つがある
- 欠損値の削除 ・・・ 3-2 で行うように列ごと削除。欠損値を含む行を削除 など
- 欠損値の補完
ここでは、欠損値の補完に関して検討していく。
まず、今のデータセットでそれぞれの欠損値がいくつあるかを再確認する
# 2つのデータセットの欠損値を確認するため、リストに登録してそれぞれに対してisnullを適用
datasets = [df_train, df_test]
for df in datasets:
display(df.isnull().sum())
print('-'*40)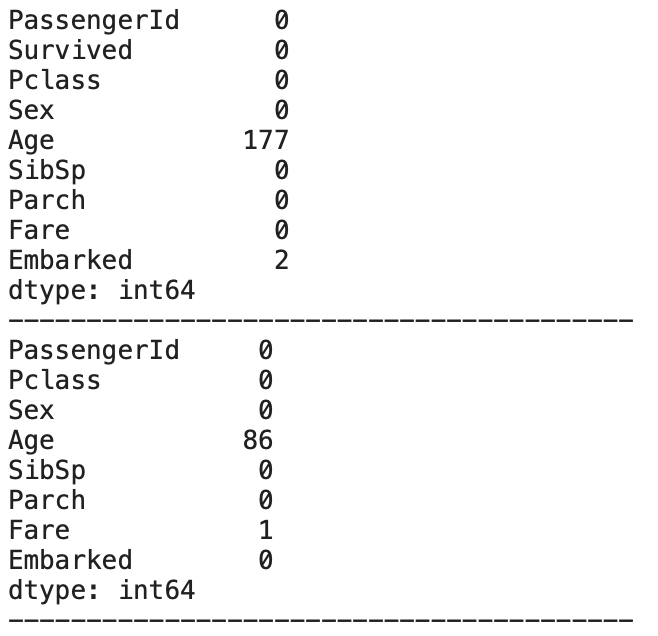
以下の数の欠損値があることがわかる
- Embarked: 2箇所 (df_train)
- Fare: 1箇所 (df_test)
- Age: 177(df_train) + 86 (df_test) の計263箇所
欠損値補完:Embarked
欠損値は2箇所だけであるので、最頻値で補完を行う
# dropna()で欠損行を削除し、modeで最頻値を求める。
# モードの出力はデータフレームで返ってくるため、スライスで欲しい値を取っている
freq_port = df_train['Embarked'].dropna().mode()[0]
freq_port
# 出力: 'S'上記より乗船港の最頻値は S であることがわかったので、欠損値をSで補完する
# fillna()で欠損値をfreq_portで穴埋めする
df_train['Embarked'] = df_train['Embarked'].fillna(freq_port)
df_train['Embarked'].info()欠損値補完:Fare
Fareは、中央値で補完を行うことを考える。ただし、FareとPclassで関係性が高いと思うため、Pclassに応じた中央値での補完を考える
まず、本当にFareとPclassで関係性を確認する
確認事項:Pclassが小さければ(高いクラス)、Fareは高い傾向があるか?
結果:Pclassが高いクラスの方が、Fareが高い傾向がある
# boxplotでPclassとFareの関係性を視覚化する
sns.boxplot(data=df_train, x='Pclass', y='Fare', palette='deep')
plt.show()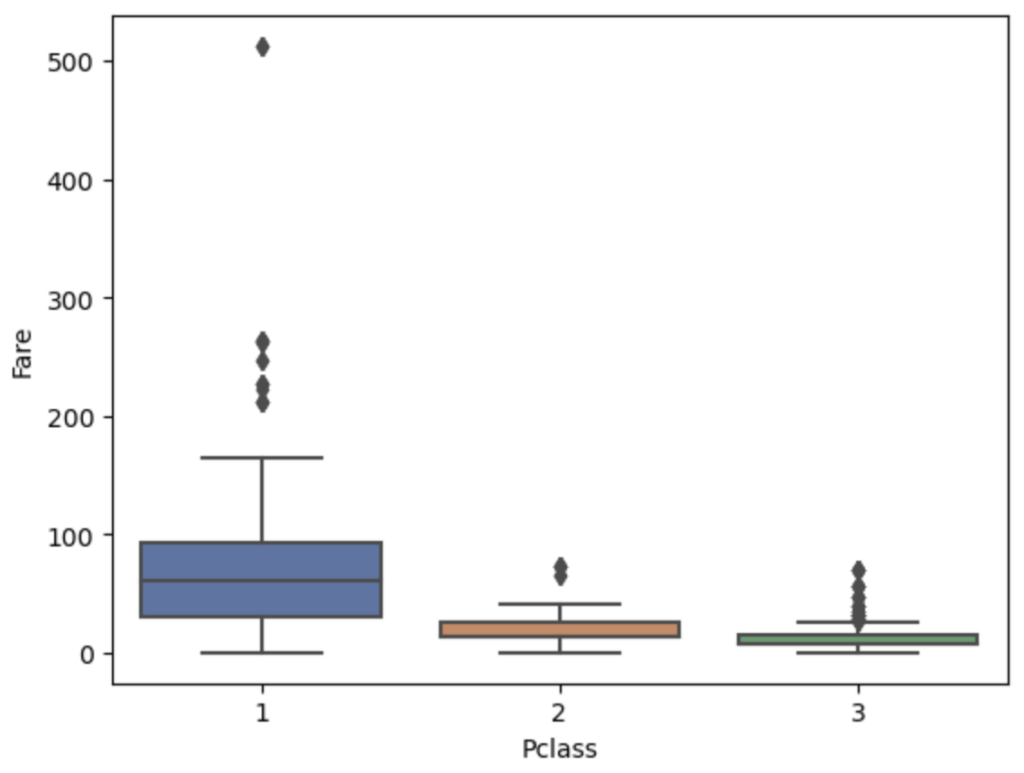
上記の結果からPclassに応じた中央値で補完を行う。下記の流れで補完を行う。
- ピポットテーブルを用いて、Pclassに対するFareの中央値を求める
- applyとlambda関数を用いて、上記に対応する値で補完を行う
# PclassごとのFareの中央値を計算したpivot_tableの作成
median_Fare = df_train.pivot_table(index='Pclass', values='Fare', aggfunc='median')
median_Fare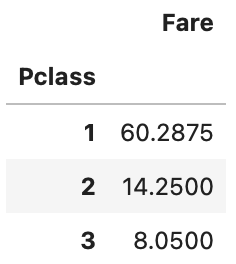
# df_testだけの補完でも問題がないが、冗長的性を持たせるために両方のデータセットに適用
datasets = [df_train, df_test]
for df in datasets:
# Fareの欠損値をPclassごとの中央値で補完
df['Fare'] = df.apply(lambda row: median_Fare.loc[row['Pclass'],'Fare'] if pd.isnull(row['Fare']) else row['Fare'], axis=1)
# 補完が出来たかの確認
df_test.isnull().sum()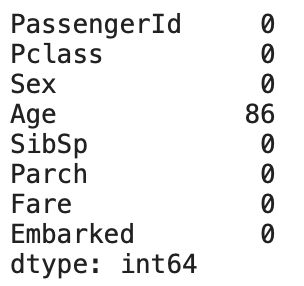
Fareが補完されていることがわかる。
* PassengerId: 1044 のFareが欠損値だったが、8.05 (Pclass: 3)で補完されている
欠損値補完:Age
Ageは、欠損値が比較的多く (計263箇所) 、平均値や中央値で補完してしまうと、元のヒストグラムのバランスを崩してしまうことになる。そのため、機械学習のランダムフォレストを用いて補完を行なっていく。
機械学習を行うためには、各データを数字に置き換える必要がある。そのため、下記の手順で補完を行なっていく。
- Ageの補完に適するパラメータを選定する
- 数字化できていない項目を数字化する
- ランダムフォレストを用いてAgeを予測し、保管する
- trainデータとtestデータを組み合わせる
- 組み合わせたデータからAgeが欠損している行を削除
- 2で作ったデータを元にランダムフォレストのモデルを構築
- 上記のモデルを使って、Ageを補完を行う
- モデルの確からしさを判断するため、欠損値補完前後のヒストグラムを比較する
現在与えられている情報からAge (年齢) を予測するパラメータとして、下記の項目を選定
パラメータ:Pclass, Sex, SibSp, Parch, Fare
* 乗船港は年齢に影響を与えないと考え除外
Sexはカテゴリーデータ (female, male) の文字列で与えられているので、数字化を行う
* 数字化においては、最終予測の機械学習時に変換が必要になるため、元データを変換する
# map関数を用いてSexの文字をそれぞれの数字に変換する
datasets = [df_train, df_test]
for df in datasets:
df['Sex'] = df['Sex'].map( {'female': 0, 'male': 1} ).astype(int)
df_train.head(3)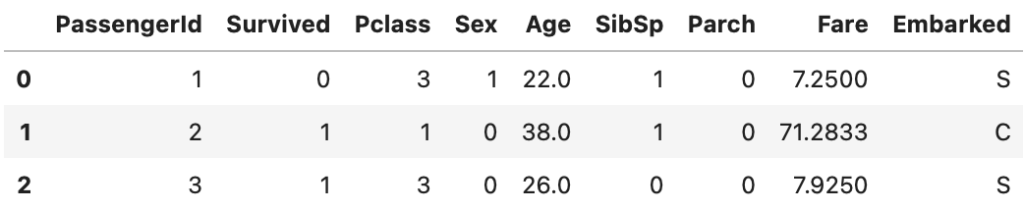
機械学習(ランダムフォレスト)を用いて欠損値のAgeを予測する
# ランダムフォレストをインポートする
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report
# パラメータをピックアップし、リストに代入しておく
features = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
# trainデータとtestデータを縦に連結
df_concat = pd.concat([df_train, df_test], ignore_index=True)
# 欠損値のない行をトレーニングデータとして使用
train_data = df_concat.dropna(subset=['Age'])
# データの前処理
X_train = train_data[features]
y_train = train_data['Age']
# ランダムフォレスト回帰モデルのトレーニング
rf_model = RandomForestRegressor(random_state=42)
rf_model.fit(X_train, y_train)
# モデルを用いてtrainデータのAgeを予測し補完
df_train.loc[df_train['Age'].isnull(), 'Age'] = rf_model.predict(df_train.loc[df_train['Age'].isnull(), features] )
# Testデータも同様に予測値を適用する
df_test.loc[df_test['Age'].isnull(), 'Age'] = rf_model.predict(df_test.loc[df_test['Age'].isnull(), features] )
# 元のヒストグラムと傾向性が違っていないかを確認する
df_concat_after = pd.concat([df_train, df_test], ignore_index=True)
fig, ax = plt.subplots(1,2,figsize=(12,5), sharey=True)
sns.histplot(data=df_concat, x='Age', bins=30, color='gray', stat='percent', ax=ax[0])
sns.histplot(data=df_concat_after, x='Age', bins=30, stat='percent', ax=ax[1])
plt.show()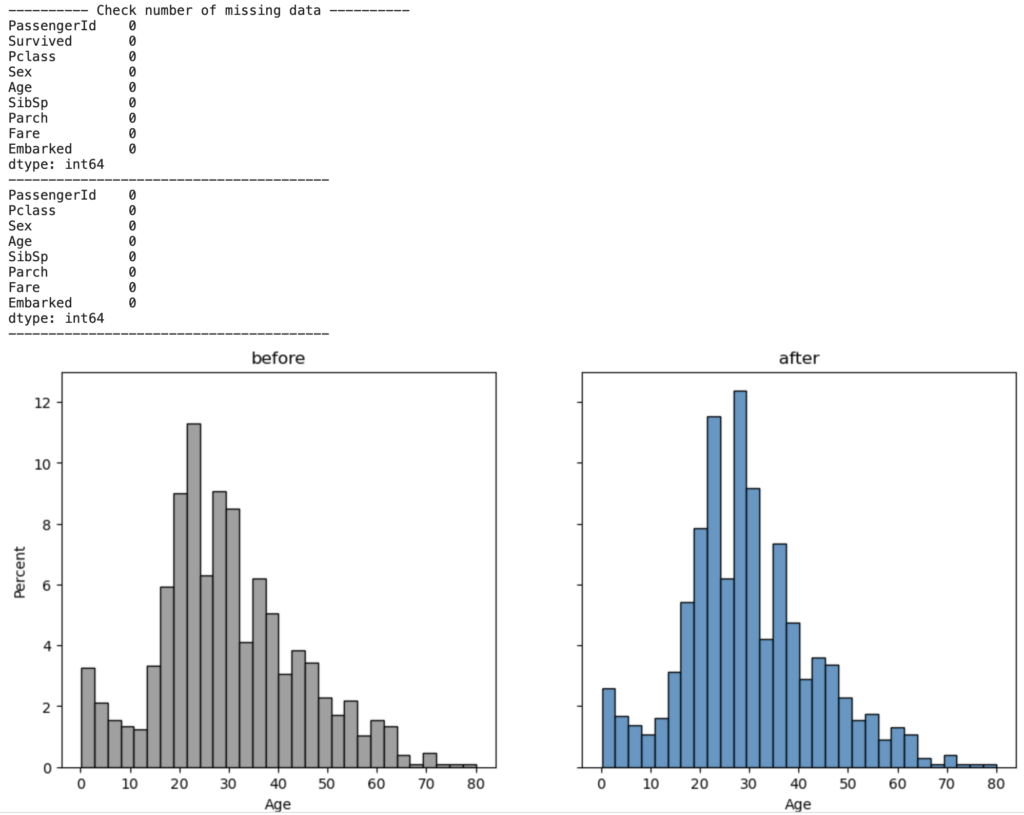
欠損値も全て補完されており、ヒストグラムの傾向性も維持されている。
機械学習 (ランダムフォレスト) を用いた補完で問題ないため、この補完で推進する
(補足) featureで与えた特徴のどの部分が予測に使われているかを求めることができる。
下記のグラフの結果から、Fare (運賃) がAgeの予測に一番影響を与えていることがわかる
# 特徴量の重要度を取得
importances = rf_model.feature_importances_
# 特徴量の重要度を降順にソートし、対応する特徴量名を取得
sorted_indices = np.argsort(importances)[::-1]
sorted_features = np.array(features)[sorted_indices]
# 特徴量の重要度を可視化
plt.figure(figsize=(4, 3))
plt.bar(sorted_features, importances[sorted_indices])
plt.xlabel('Features')
plt.ylabel('Importance')
plt.title('Feature Importance of Random Forest Model')
plt.xticks(rotation=45)
plt.show()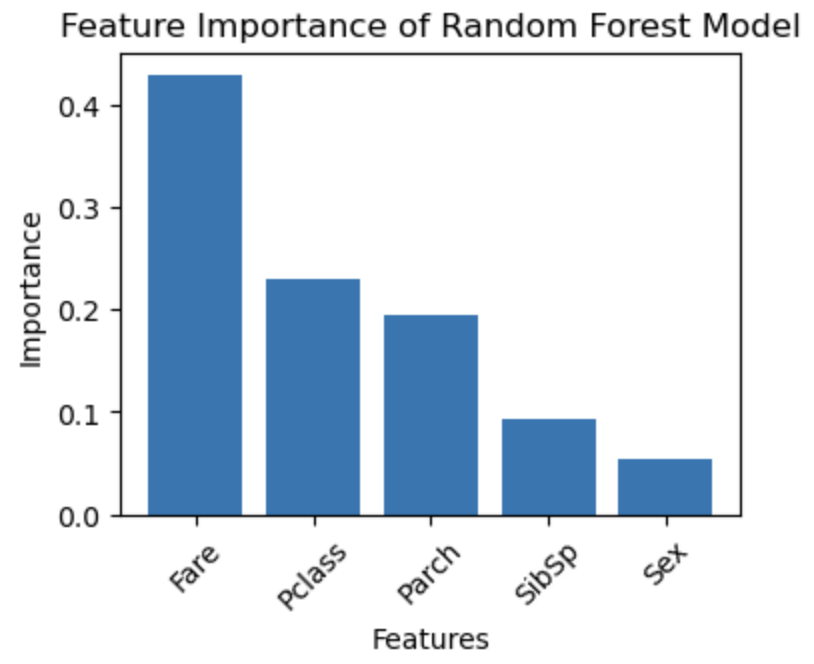
3-4. 外れ値の処理
Fareに一部値が外れている部分はあるが、次の特徴の前処理で区間分けを行うため、今回のデータはで対応せずに推進する
* 実際のデータでは、測定器ミスや記載ミスなども含むため、外れ値の内容を理解し、それに対して適切な処理 (除外、そのまま扱う、修正などを行う必要がある)
3-5. 特徴量の前処理
本問題は、生存かそうではないかのカテゴリー分け問題の一種になる。また、各パラメータもAgeとFareを除くと、カテゴリーデータとなっている
そのため、AgeとFareもカテゴリー化を行い、全てのパラメータをカテゴリーに合わせることにより機械学習の精度を上げることを考える
特徴量の前処理としては、下記の対応を行なっていく
- Fare: 数値データを5つのカテゴリーに分ける (特徴量エンジニアリング)
- Age: 数値データを5つのカテゴリーに分ける (特徴量エンジニアリング)
- Embarked:カテゴリーデータを数字に置き換える (カテゴリーデータの処理)
特徴量エンジニアリング:Fare
Fareは、0 ~ 512 の範囲でかつ、平均が 32 と非常に偏りがあるデータとなっている。
( describe を参照 )
上記を踏まえ、Fareの手法としては、pd.qcutを使用する
分割 (ビン分割) 方法としては、主に下記の2つがあり、目的により使い分ける
| メソッド | pd.cut | pd.qcut |
|---|---|---|
| 説明 | データを指定した区間に均等に分割します。 | データを指定した区間に等しく分位点で分割します。 |
| カテゴリーの幅が一定で、データを等間隔で分割します。 | カテゴリーの幅はデータの分布に基づいて調整され、 | |
| カテゴリーの範囲は指定した区間になります。 | 各カテゴリーにデータ数が近くなるようにします。 | |
| 使用例 | pd.cut(data, bins=3) | pd.qcut(data, q=4) |
# trainデータとtestデータの両方を踏まえて、Fareを5分割にするFareBandを作る
df_concat = pd.concat([df_train, df_test], ignore_index=True)
# Fareを5つのビンに分割して境界値を取得
# pd.qcut(df_train['Fare'], 4) で Fare列の値それぞれに対して、どの区間にあるかを示す
# unique()関数を用いて分割項目を取り出し、ソートを行う
# interval (-0.001, 7.91] の項目が取得できるため、interval.right で右側の値を取得(内包表記使っている)
# 先頭の[-1]は、pd.cutの時の最小値の設定のため。0設定だと、0がNaNになってしまう
boundary_Fare = [-1] + [interval.right for interval in sorted(pd.qcut(df_concat['Fare'], 5).unique())]
boundary_Fare[-1] = boundary_Fare[-1] + 1 # pd.cutの際に最大値がNaNにならないように1をたす(小数点対策)
print(f'boundary_Fare: {boundary_Fare}')
# 各データセットをboundary_Fareを当てはめていく。pd.cutでbins毎に区間分けができる
datasets = [df_train, df_test]
for df in datasets:
df['FareBand'] = pd.cut(df['Fare'], bins=boundary_Fare, labels=False)
df_train.head(3)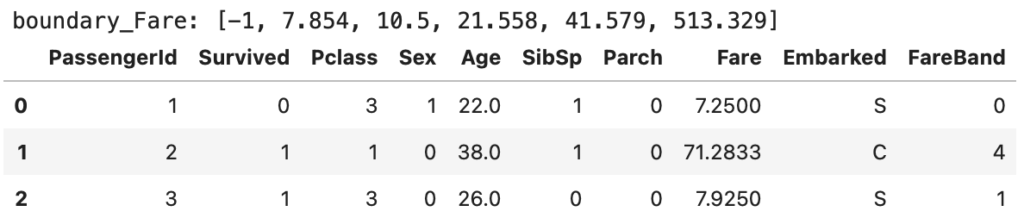
pd.cutでは、boundary_Fareのビン範囲を用いることにより、下記の分割となる
| データ範囲 | ラベル |
|---|---|
| -1 ~ 7.854 | 0 |
| 7.854 ~ 10.5 | 1 |
| 10.5 ~ 21.558 | 2 |
| 21.558 ~ 41.579 | 3 |
| 41.579 ~ 513.329 | 4 |
特徴量エンジニアリング:Age
Ageに関しても上記同様にビン分割を行なっていく。Fareではデータの偏りが見られたため、pd.qcutを用いて分布を考慮した分割を行なった。
Ageに関しては、一様に分布しているため、年齢を単純に5分割を行う
# trainデータとtestデータの両方を踏まえて、Ageを5分割にするFareBandを作る
df_concat = pd.concat([df_train, df_test], ignore_index=True)
# Ageを均等に5つに分割し境界値を取得
boundary_Age = [-1] + [interval.right for interval in sorted(pd.cut(df_concat['Age'], 5).unique())]
boundary_Age[-1] = boundary_Age[-1] + 1 # pd.cutの際に最大値がNaNにならないように1をたす(小数点対策)
print(f'boundary_Age: {boundary_Age}')
datasets = [df_train, df_test]
for df in datasets:
df['AgeBand'] = pd.cut(df['Age'], bins=boundary_Age, labels=False)
df_train.head(3)
カテゴリーデータの処理:Embarked
乗船港 (Embarked) は、S, C, Q で表記されているため、数字に置き換える。やり方は、性別 (Sex) の時に適用した方法と同様にmap関数を用いる
# trainとtestの両方に適用するために、データセットをまとめる
datasets=[df_train, df_test]
# S: 0, C: 1, Q: 2 に変換する
for df in datasets:
df['Embarked'] = df['Embarked'].map({'S': 0, 'C': 1, 'Q': 2})
df_train.head(3)
3-6. データの分割
データの確認と前処理が非常に長かったのですが、やっと最後の段階ですが、この部分は機械学習の一部に入れてしまっていいと思いますし、データ準備の所で一緒に行なってもいいです。
ここでは、下記の項目を行なっていく
- 機械学習に用いるパラメータを選定する
- 説明変数X, 目的変数y を設定する
- データを分割する
3-6-1. パラメータの選定
データの前処理で作成したパラメータを考慮して今回は下記のパラメータを使用する
# 特徴量の選択し、featuresに格納する
features = ['Pclass', 'Sex', 'AgeBand', 'SibSp', 'Parch', 'FareBand', 'Embarked']3-6-2. 説明変数X, 目的変数y の設定
説明変数と目的変数は言葉では難しく感じるが、今回のデータはでは下記に当たる。
| 変数の種類 | 説明 | 今回のデータ |
|---|---|---|
| 目的変数 | 予測や解釈の対象となる変数。モデルが予測する対象。 | Survived |
| 説明変数 | 目的変数に影響を与える要因となる変数。モデルの入力として使われる。 | ‘Pclass’, ‘Sex’, ‘AgeBand’, ‘SibSp’, ‘Parch’, ‘FareBand’, ‘Embarked’ |
# 機械学習では、trainデータを用いて精度を確認し、提出時にtestデータを用いる。
X = df_train[features]
y = df_train['Survived']3-6-3. データの分割
今回はHOLD-OUT法を用いてデータを分割を行う。
train_test_splitをインポートすることにより、簡単にランダムな分割を行うことができる
# HOLD-OUT法を用いるため、ライブラリーをインポート
from sklearn.model_selection import train_test_split
# データをトレーニング用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f'X_train: {X_train.shape}, X_test: {X_test.shape}')
X_train.head(5)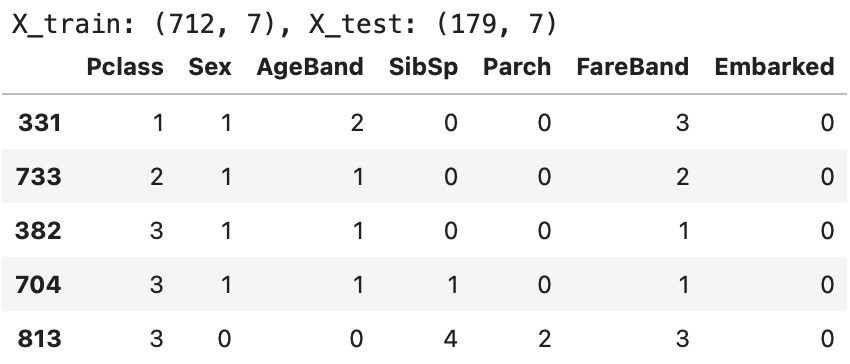
891行あるdf_trainを 712 (X_train) , 179 (X_test) に分割し、かつランダムデータになっている
分割比率は、test_size =0.2(20%) 、random_stateはランダムな仕方を固定するため。
(random_stateを固定しないと、実行する度に値が変わり、モデルの検証が難しい)
参考) データの分割方法の種類と特徴
| データの分割方法 | 特徴 |
|---|---|
| HOLD-OUT法 | データセットをトレーニングセットとテストセットに2つに分割します。典型的な分割比率は、トレーニングセットが全体の70〜80%、テストセットが20〜30%です。単純で実装が容易ですが、データセットの分布によってテストセットの性能が変動する可能性があります。 |
| K-Fold交差検証法 | データセットをK個のフォールド(ブロック)に分割します。K回の実験を行い、各フォールドを1回ずつテストセットとし、残りのK-1個をトレーニングセットとします。K-Fold交差検証は、データセット全体を利用して複数のモデルを評価するため、評価の信頼性が高いと言えます。 |
| Leave-One-Out交差検証法 | K-Fold交差検証の特殊なケースであり、データセットの各サンプルを1つだけテストセットとして使用します。データセットが小さい場合や過学習を防ぐ必要がある場合に使用されます。計算コストが高いという欠点があります。 |
| Stratified K-Fold交差検証法 | K-Fold交差検証の改良版であり、クラスの分布を考慮してサンプルを分割します。クラスの割合が均等になるようにすることで、偏ったデータセットやクラスの分布が偏った場合でも適切な評価ができます。 |
| Time Series Cross-Validation | 時系列データに適用される交差検証法で、データを時間の経過に沿って分割します。時系列データの特性を考慮して、未来のデータをテストセットに使用することで、モデルの未来予測性能を評価します。 |
| Group K-Fold交差検証法 | 特定のグループやクラスターの間でデータを分割します。例えば、同じ患者から得られたデータをグループとして扱い、同じ患者のデータがトレーニングセットとテストセットの両方に入らないようにします。データの依存性を考慮して評価します。 |
4. データモデリング
いよいよ機械学習のパートにやってまいりました。やっと本番!っと思う所なのですが、機械学習自体は既に有益なライブラリがあるので、インポートして実行を押すとすぐに結果を返してくれます。
初めは『えっ。これだけ』っとなります(なりました)。では、早速実装していきましょう。
4-1. 機械学習の手順
モデリングはskit-learnの各モデルを用いる。skit-learnを用いた場合は、同じ手順でモデリングから予測まで行うことができる。以下が手順になる
(同じ手順で実装できるので、非常に楽です)
| ステップ | コード例 | 説明 |
|---|---|---|
| 1. データの準備 | X_train, X_test, y_train, y_test を用意 | トレーニングデータ(X_train, y_train)とテストデータ(X_test, y_test)を用意します。 |
| 2. モデルのインポート | from sklearn.ensemble import RandomForestClassifier | モデルのライブラリをインポートします。 |
| 3. モデルのインスタンス化 | model = RandomForestClassifier(random_state=42) | モデルのインスタンスを作成します。 |
| 4. モデルのトレーニング | model.fit(X_train, y_train) | トレーニングデータを使ってモデルを学習させます。 |
| 5. モデルの予測 | y_pred = model.predict(X_test) | テストデータを使ってモデルから予測を行い、予測結果を取得します。 |
| 6. モデルの評価 | accuracy = accuracy_score(y_test, y_pred) | モデルの精度を計算し、テストデータに対する精度を示す指標を取得します。 |
| 7. 精度の可視化やその他の評価 | 精度やその他の評価指標を可視化したり、必要に応じて他の評価を行います。 | 可視化や他の評価を行い、モデルの性能をより詳細に理解し、改善するための情報を得ることがあります。 |
4-2. 機械学習モデルの種類
今回8つのモデルで機械学習を行なっていく。
(ここの詳細な説明は公式HPなどでご確認をお願い致します。勉強中で理解が追いついていないです)
| モデル | 説明 |
|---|---|
| ロジスティック回帰 | ロジスティック回帰は、データの線形分離可能性を用いて確率をモデル化し、分類を行うモデルです。シグモイド関数により確率を0から1の範囲に制限します。 |
| 決定木 | 決定木はデータを階層的に分割して予測を行う分類・回帰モデルです。分割基準は情報利得やジニ不純度などが使われます。 |
| ランダムフォレスト | ランダムフォレストは、複数の決定木を組み合わせて予測を行うアンサンブル学習法です。データのブートストラップサンプリングとランダムな特徴の選択が特徴的です。 |
| K最近傍法 | K最近傍法は、新しいデータに対して、トレーニングデータの中から距離が最も近いK個のデータ点を参照して、多数決などにより予測を行います。 |
| サポートベクターマシン | サポートベクターマシンは、データを高次元空間にマッピングし、超平面によってデータを分類するモデルです。マージン最大化により最適な超平面を求めます。 |
| 線形SVC(サポートベクターマシン) | 線形SVCは、サポートベクターマシンの一種で、データを線形超平面によって分類するモデルです。マージン最大化により最適な超平面を求めます。 |
| 確率的勾配降下法 | 確率的勾配降下法は、最適化アルゴリズムの一つで、モデルのパラメータを最適化する手法です。機械学習の多くのモデルで学習に利用されます。 |
| パーセプトロン | パーセプトロンは、ニューラルネットワークの一種で、複数の入力に対して重み付き和を計算し、活性化関数を用いて予測を行います。 |
| ナイーブベイズ | ナイーブベイズは、ベイズの定理を用いて分類を行う確率モデルです。特徴の条件付き独立性を仮定し、計算効率が高いことが特徴です。 |
4-3. モデルの評価
モデルの評価として、今回は2つの種類(正解率とAUC)を用いる。それぞの特徴は下記になる
| 特徴 / 評価指標 | 正解率(Accuracy) | AUC-ROC |
|---|---|---|
| 対象 | 全体の予測の精度 | 陽性クラスと陰性クラスの分離度 |
| 強調すること | クラスの予測全体の正確さ | 陽性クラスと陰性クラスの分離度を高めること |
| 分類バランス | クラスのバランスが均衡している場合に有用 | クラスのバランスに関係なく使用可能 |
| 公平性 | クラスのバランスによって影響を受ける | クラスバランスに依存しない |
| 適用例 | クラスのバランスが均等な場合や、全体の予測精度を評価する場合 | クラスのバランスに関係なく、陽性クラスと陰性クラスの分離度を評価する場合 |
| 評価式 | (TP+TN) / (TP+TN+FP+FN) | ROC曲線の下の面積 |
| 値の範囲 | 0から1まで | 0から1まで、AUCが大きいほど性能が高い |
上記の表の中の、TP, TN, FP, FN は下記になる。つまり、予測 2つ に対して、True, Falseを分類している
| 評価結果 / 真のクラス | 陽性(Positive) | 陰性(Negative) |
|---|---|---|
| 陽性(Positive) | TP (True Positive) | FN (False Negative) |
| 陰性(Negative) | FP (False Positive) | TN (True Negative) |
4-4. 実装
ロジステック回帰
まず、各モデルのスコアを入れるためのデータフレームを準備する
df_scores = pd.DataFrame(columns=['score','AUC'])各モデルの結果をdf_scoresにも追加していく
from sklearn.linear_model import LogisticRegression
# ロジスティック回帰モデルのインスタンスを作成(インスタンス名をlogregにしている)
logreg = LogisticRegression()
# トレーニングデータを用いてモデルの学習を行う
logreg.fit(X_train, y_train)
# テストデータを使って予測を行い、予測結果をY_predに格納する
y_pred = logreg.predict(X_test)
# モデルの精度(学習データに対する精度)を計算し、acc_logに格納する
acc_log = round(logreg.score(X_test, y_test) * 100, 2)
df_scores.loc['acc_log','score'] = acc_log
print(f'acc_log: {acc_log}')
#出力 acc_log: 80.06AUCの性能評価は下記になる。
# ROC曲線を計算
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
# AUCを計算
auc = round(roc_auc_score(y_test, y_pred) * 100, 2)
# スコアのデータフレームに追加
df_scores.loc['log','AUC'] = auc
# AUCを表示
print("AUC_log:", auc) #AUC_log: 78.96
# ROC曲線をプロット
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='b', lw=2, label='ROC curve')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--', lw=2)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()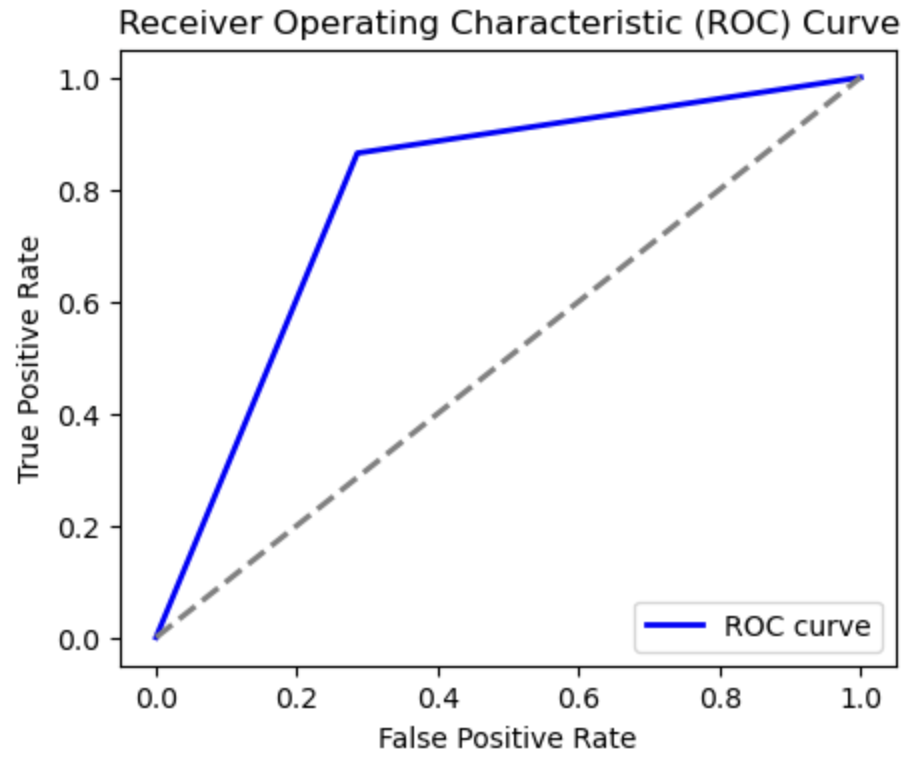
AUC (Area Under the Curve) の略であり、上記の青線の下の面積をさす。縦軸が真陽性 (True Positive) を表すため、数字が 1 に近い方がいいモデルになる
* 以降はコメントとAUCのグラフを省略
決定木
from sklearn.tree import DecisionTreeClassifier
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, y_train)
y_pred = decision_tree.predict(X_test)
acc_decision_tree = round(decision_tree.score(X_test, y_test) * 100, 2)
df_scores.loc['acc_decision_tree','score'] = acc_decision_tree
print(f'acc_decision_tree: {acc_decision_tree}')
#出力 acc_decision_tree: 88.48
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
auc = round(roc_auc_score(y_test, y_pred) * 100, 2)
df_scores.loc['decision_tree','AUC'] = auc
print("AUC_decision_tree:", auc)
#出力 AUC_decision_tree: 80.3ランダムフォレスト
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, y_train)
y_pred = random_forest.predict(X_test)
random_forest.score(X_train, y_train)
acc_random_forest = round(random_forest.score(X_test, y_test) * 100, 2)
df_scores.loc['acc_random_forest','score'] = acc_random_forest
print(f'acc_random_forest: {acc_random_forest}')
#出力 acc_random_forest: 88.48
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
auc = round(roc_auc_score(y_test, y_pred) * 100, 2)
df_scores.loc['random_forest','AUC'] = auc
print("AUC_random_forest:", auc)
#出力 AUC_random_forest: 82.8K最近傍法
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
acc_knn = round(knn.score(X_test, y_test) * 100, 2)
df_scores.loc['acc_knn','score'] = acc_knn
print(f'acc_knn: {acc_knn}')
#出力 acc_knn: 84.83
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
auc = round(roc_auc_score(y_test, y_pred) * 100, 2)
df_scores.loc['knn','AUC'] = auc
print("AUC_knn:", auc)
AUC_knn: 77.79サポートベクターマシン
from sklearn.svm import SVC, LinearSVC
svc = SVC()
svc.fit(X_train, y_train)
y_pred = svc.predict(X_test)
acc_svc = round(svc.score(X_test, y_test) * 100, 2)
df_scores.loc['acc_svc','score'] = acc_svc
print(f'acc_svc: {acc_svc}')
#出力 acc_svc: 82.87
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
auc = round(roc_auc_score(y_test, y_pred) * 100, 2)
df_scores.loc['svc','AUC'] = auc
print("AUC_svc:", auc)
#出力 AUC_svc: 80.3線形SVC(サポートベクターマシン)
# ライブラリは上記ですでにインポート済み
linear_svc = LinearSVC(max_iter=10000) #収束せずにWarningが出たため反復回数を増やした
linear_svc.fit(X_train, y_train)
y_pred = linear_svc.predict(X_test)
acc_linear_svc = round(linear_svc.score(X_test, y_test) * 100, 2)
df_scores.loc['acc_linear_svc','score'] = acc_linear_svc
print(f'acc_linear_svc: {acc_linear_svc}')
#出力 acc_linear_svc: 79.35
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
auc = round(roc_auc_score(y_test, y_pred) * 100, 2)
df_scores.loc['linear_svc','AUC'] = auc
print("AUC_linear_svc:", auc)
#出力 AUC_linear_svc: 78.19確率的勾配降下法
from sklearn.linear_model import SGDClassifier
sgd = SGDClassifier()
sgd.fit(X_train, y_train)
y_pred = sgd.predict(X_test)
acc_sgd = round(sgd.score(X_test, y_test) * 100, 2)
df_scores.loc['acc_sgd','score'] = acc_sgd
print(f'acc_sgd: {acc_sgd}')
#出力 acc_sgd: 55.06
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
auc = round(roc_auc_score(y_test, y_pred) * 100, 2)
df_scores.loc['sgd','AUC'] = auc
print("AUC_sdg:", auc)
#出力 AUC_sdg: 78.84パーセプトロン
from sklearn.linear_model import Perceptron
perceptron = Perceptron()
perceptron.fit(X_train, y_train)
y_pred = perceptron.predict(X_test)
acc_perceptron = round(perceptron.score(X_test, y_test) * 100, 2)
df_scores.loc['acc_perceptron','score'] = acc_perceptron
print(f'acc_perceptron: {acc_perceptron}')
#出力 acc_perceptron: 75.98
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
auc = round(roc_auc_score(y_test, y_pred) * 100, 2)
df_scores.loc['perceptron','AUC'] = auc
print("AUC_perceptron:", auc)
#出力 AUC_perceptron: 70.12ナイーブベイズ
from sklearn.naive_bayes import GaussianNB
gaussian = GaussianNB()
gaussian.fit(X_train, y_train)
y_pred = gaussian.predict(X_test)
acc_gaussian = round(gaussian.score(X_test, y_test) * 100, 2)
df_scores.loc['acc_gaussian','score'] = acc_gaussian
print(f'acc_gaussian: {acc_gaussian}')
#出力 acc_gaussian: 77.25
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
auc = round(roc_auc_score(y_test, y_pred) * 100, 2)
df_scores.loc['gaussian','AUC'] = auc
print("AUC_gaussian:", auc)
#出力 AUC_gaussian: 78.965. モデルの評価と改良
5-1. モデルの精度
データモデリングで求めた精度の一覧をまとめ降順に並べ替えると以下になる
df_scores.sort_values(by='AUC',ascending=False)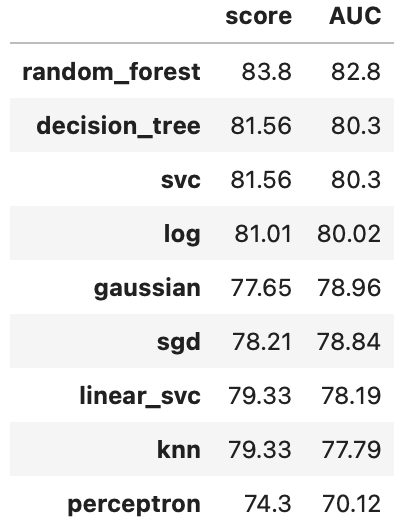
評価方法により精度のばらつきが発生するが、今回の結果においてはランダムフォレストが一番高い精度があることがわかる
5-2. 特徴量の重要度
今回の特徴量の中でどの項目が一番Survivedに影響を与えていたかを確認する
# 特徴量の重要度を取得
importances = random_forest.feature_importances_
# 特徴量の重要度を降順にソートし、対応する特徴量名を取得(argsortでインデックス番号を取得)
sorted_indices = np.argsort(importances)[::-1]
sorted_features = np.array(features)[sorted_indices]
# 特徴量の重要度を出力 (Zipを用いることで、それぞれのリストから同時に値を取ってくる)
for imp, v in zip(sorted_features, importances[sorted_indices]):
print(f'{imp}: {v.round(3)}')
print('-'*53)
# 特徴量の重要度を可視化
plt.figure(figsize=(4, 3))
plt.bar(sorted_features, importances[sorted_indices])
plt.xlabel('Features')
plt.ylabel('Importance')
plt.title('Feature Importance of Random Forest Model')
plt.xticks(rotation=45)
plt.show()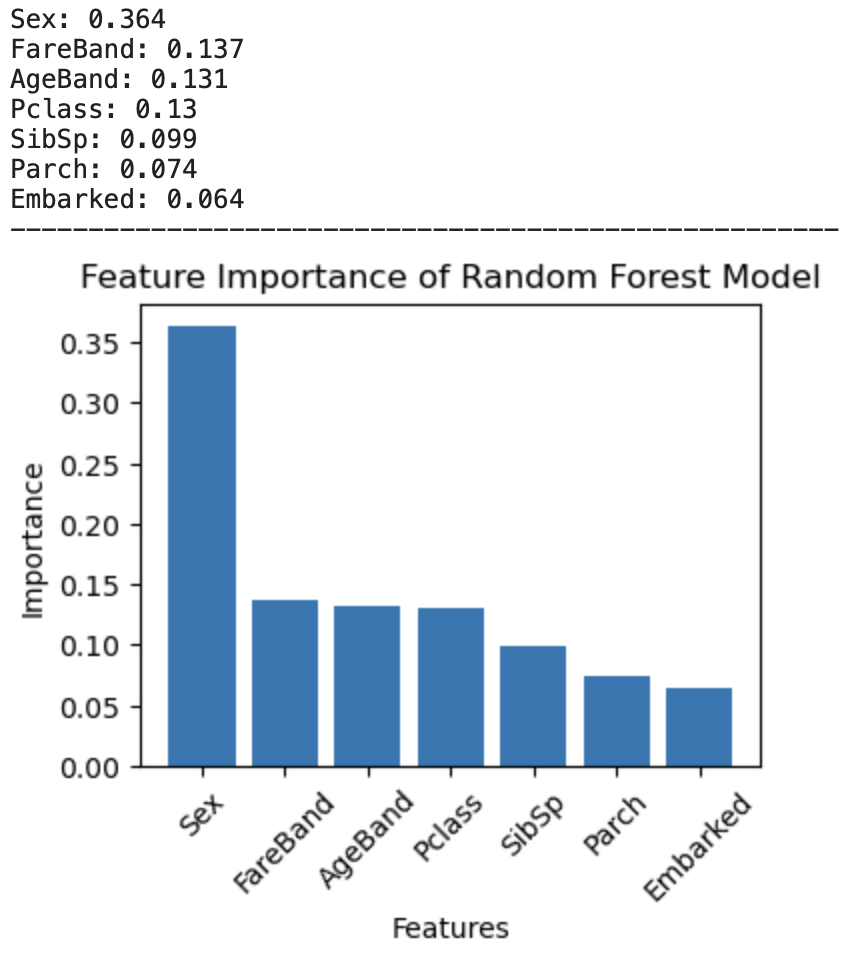
性別 (Sex) が Survived に最も大きな要因であることがわかる
また、ロジスティック回帰においては、予測値を式として扱うことができる。今回は分類問題のため、解答が0, 1 であるが、回帰問題(数値予測) などにおいて有益である。下記を用いることにより各特徴量の係数を求めることができる
# 各特徴量をデータフレームとして表示するために、新たなデータフレームを作る
coeff_df = pd.DataFrame(index=features, columns=['Correlation'])
# ロジステック回帰モデルをモデル化した logreg の coef_[0] にリストで各要素の
coeff_df['Correlation'] = logreg.coef_[0]
coeff_df.sort_values(by='Correlation', ascending=False)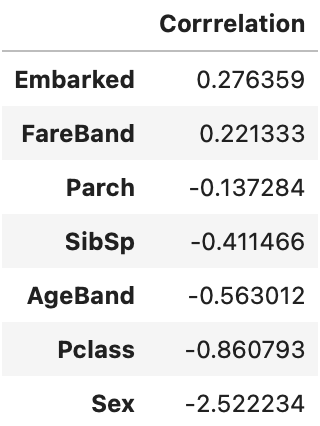
各係数の特徴量は、下記を示している
- 数字の絶対値・・・大きい方がモデルに与える影響が大きい
- 符号・・・マイナス: 予測に対して各項目が負の関係、プラス:予測に対して各項目が正の関係
- 性別(Sex)が 0: 女性の方が、生存(Survived)が1になりやすいことを示している
モデルにより重要項目が変わるため精度が異なる。ただし、性別の影響はどちらの場合でも1番目に来ているため、性別が大きいことが機械学習でもわかる
6. 結果の可視化と報告
いよいよ終わりに近づいてきました。
モデルの精度・重要度も考慮しながら、事前に行なったデータの可視化も入れつつ結果をまとめる。(自分の場合は、1年後の自分でわかる内容にまとめることを目標にしています)
6-1. (Kaggle)提出形態へ整形
Kaggleにおいては、要望の提出形態で出力する最後の工程を実装する
今回、ランダムフォレストが一番精度が高かったため、ランダムフォレストを用いる
# テストデータを用いて予測を行う
y_submit = random_forest.predict(df_test[features])
# 予測結果をテストデータの新しい列 'Survived' として追加
df_test['Survived'] = y_submit
# 提出用のデータフレームを作成し、'PassengerId' と 'Survived' 列を選択
submission_df = df_test[['PassengerId', 'Survived']]
# 提出用データフレームを表示
display(submission_df)
# 提出用の CSV ファイルとして保存(インデックス列を含まないように index=False を指定)
submission_df.to_csv('submission.csv', index=False)
6-2. (Kaggle)データ提出
下記の手順に従ってデータを提出する
- 今回のコード上にて Save version -> Save & Run All (commit)であることを確認しSave を実施する
- 暫くコードが実行 -> successful が出ることを確認する
- 上記のsuccessfulの右側にある ・・・ マークをクリックし、Open in view をクリック
- 新たなページが開かれ、自身のコードが表示される
- 右上の Edit の隣の縦3点マークをクリック -> Submit Competition を選ぶ
- 新たなPop-upが表示される( 現状のNotebook情報が記載されている)-> 右下のSubmitをクリック
- Submissionsページに飛び、今回の結果(Score)が表示される
* Public score: 0.75119 でした。約75%の正解率。
1日10回まで提出可能ですので、モデルを変えたり、検証方法を変えても正解率が高くなる方法を探索する。
更に、データ整形の仕方を見直したり、モデルのパラメータを変えることにより正解率を高めていく。
7. 応用と展望
実務においては、今回のモデルをシステム化を行なったり、更なる解析に繋げることになると思います。
*現状の私では経験不足で、詳細は専門家のページを参考にしてください。
感想
始めに、このブログを訪れてくださり、ありがとうございます!(゚▽゚*) 40代のサラリーマンがプログラミングの扉を開く冒険の日々をお伝えしています。私も最初は軽い気持ちで機械学習の世界に足を踏み入れてみましたが、まさに予想以上の大冒険となりました(笑)。
第一回目の記事では、私と同じくプログラミング初心者の皆さんに向けて、Kaggleというデータ解析の素晴らしい舞台裏をご紹介しました。具体的には、あの有名なTitanicのデータを使った生存予測コンペに挑戦しました。プログラミングの世界は奥が深く、初めての方でもわかりやすいように解説していきましたが、まだまだ改善の余地がありそうです。(´・ω・`) これからもっとわかりやすく、楽しく解説していきたいと考えています。
そして、気になる結果の方ですが、正直言ってまだまだです(汗)。ですが、そこにはまだまだ可能性が広がっているんです!これからも引き続き精進し、更なるステップアップを目指して頑張っていきます!٩(◕‿◕。)۶
さて、次回以降の更新については、一月に一度の更新ペースを心掛けています。次回の記事もお楽しみにしていてくださいね!ヾ(^∇^)
最後に、今回の記事が少しでも皆さんのプログラミングの一歩になれれば嬉しいです。私と一緒に、楽しく学んでいきましょう!٩(。•ω•。)و これからも皆さんの成長を応援しています!


コメント